最近在楼下停车场散步,反思了一下最近遇到的bug,觉得蛮有意思的,写篇blog分享一下。
上文我们已经从架构的方面去讨论过多种的agent架构,主要还是分为隐式plan、半显式plan和显式plan的三种不同的agent风格,
那么在前年的prompt engineering的时代,RAG是那时候的热门话题,为什么要RAG呢,是因为LLM落地的第一大问题:大模型训练的语料是公开语料和通用规律,它是不知道公司内部文档、你自己的笔记和古早之前的上下文的,那时候连web search的清洗都是非常困难的,所以大模型的幻觉非常强。
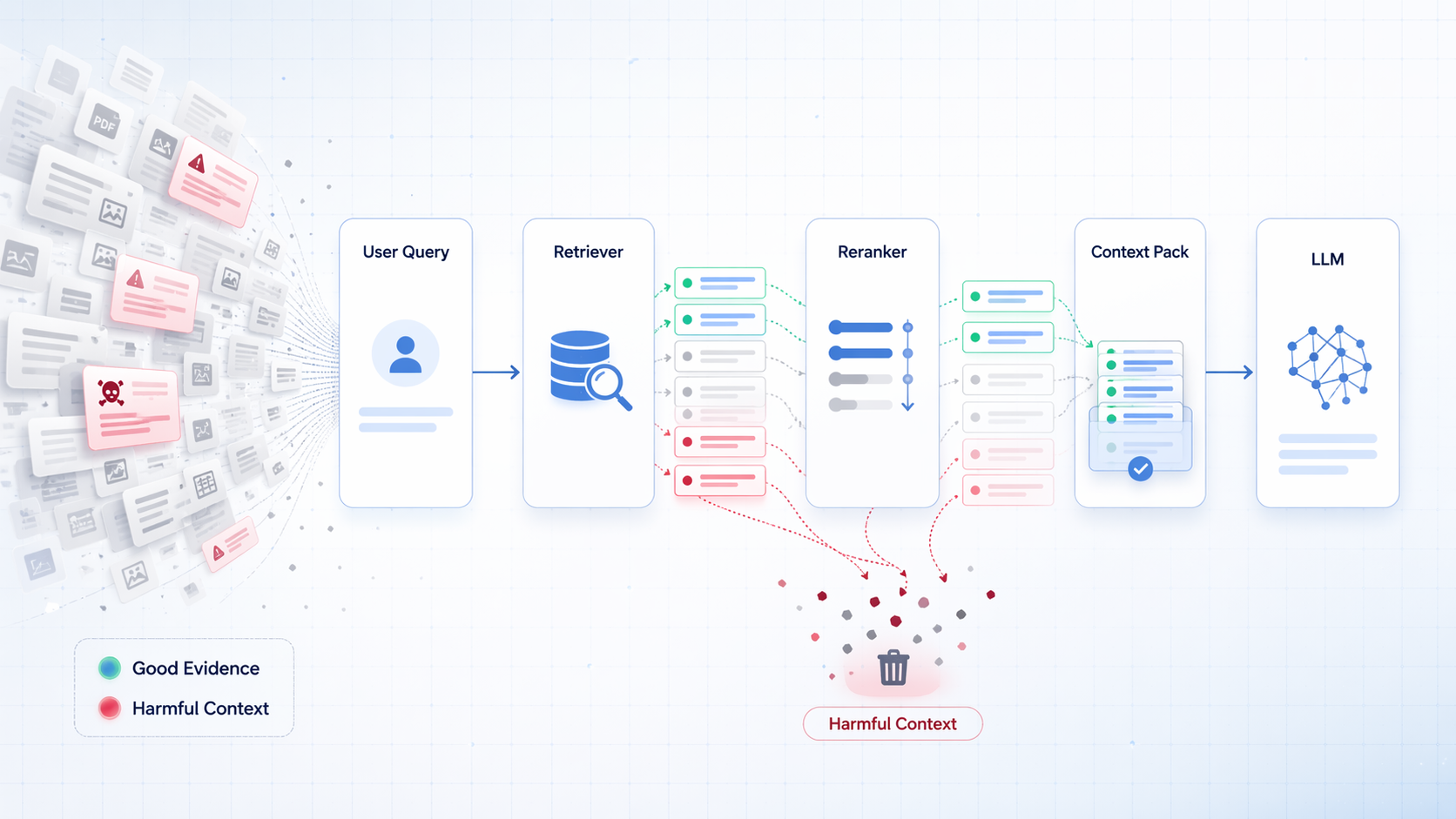
RAG作为一个能力层,要做的就是embedding、chunked、检索召回、rerank这种非常常用的workflow,这些都是func call的tools use,所以那个时候已经开始修工具了,那时候面临的最大的两个问题,一个是召回的时候搜不准,第二个就是组织context给LLM组织的不好。
很多人刚做 RAG 时,第一反应是把 top_k 拉大:k=5 不够就上 k=20,dense 不够就 hybrid,hybrid 不够就再堆 reranker。结果常见现象不是答案更稳,而是上下文更多了,回答反而更飘了。这两年,尤其是 2024 和 2025,RAG 检索侧一个非常明确的结论慢慢成形:问题不只是 recall 不够,而是 retrieved context 里混进了太多“看起来相关、其实会害人”的东西。
2024 年不少工作开始正面这个问题,比如从 chunk 粒度、query rewriting、树/图结构检索、long-context retrieval、reranking 一路拆。很多 RAG 系统默认把用户原问题直接拿去检索,但真实 query 常常是带省略、带指代、带上下文依赖、带任务意图混杂的。
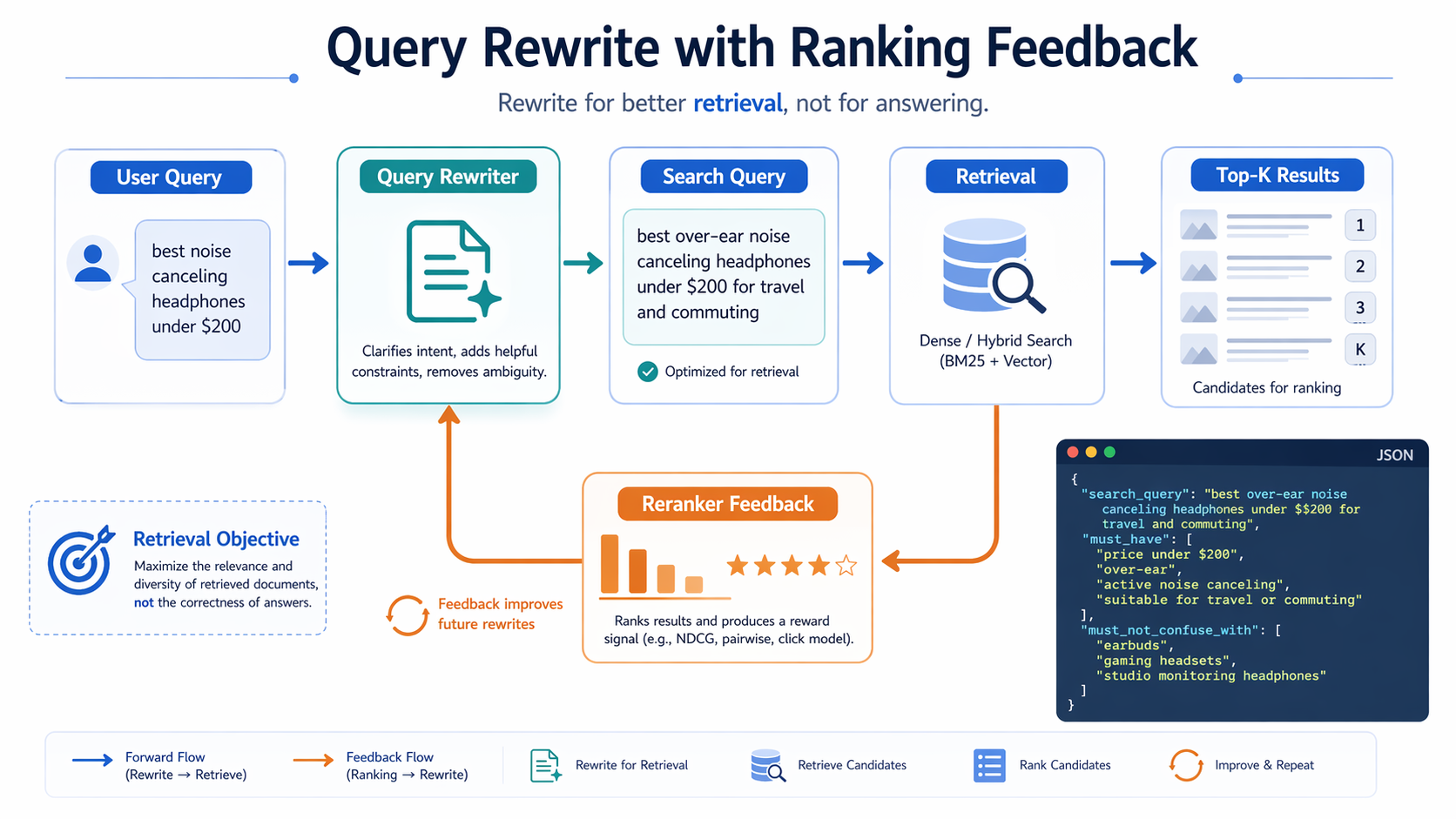
那时候就提出了RAG 里 query rewrite 不是锦上添花,相关工作还提出用 ranking feedback 来改写 query,让改写不是只看“像不像自然语言问题”,而是看“是否更能检到好文档”。最朴素但非常有效的代码是把检索目标显式写进 prompt:
def rewrite_query(llm, user_query, chat_history=None):
prompt = f"""
You are rewriting a query for retrieval, not for answering.
Goal:
1. Remove vague references.
2. Expand missing key entities.
3. Preserve factual constraints.
4. Generate a search-oriented query, not a conversational reply.
User query:
{user_query}
Return JSON:
{{
"search_query": "...",
"must_have": ["..."],
"must_not_confuse_with": ["..."]
}}
"""
return llm(prompt)这类改法的关键不在“变长”,而在把 retrieval objective 写出来。否则改写器很容易把 query 改得更流畅,但更不利于召回。这个思路和 ranking-feedback 方向是一致的:query rewrite 应该对检索结果负责,而不是只对语言表面负责。2025 年这条线又进一步发展成了带多方面反馈的 MaFeRw:先取 top-K,再让 reward/reranker 信号反哺 query rewriter。
另一条 2024 年很有代表性的路线是 LongRAG。它直截了当地指出,传统 RAG 往往让 retriever 在海量短 chunk 里找“针”,retriever 很重,reader 却很轻,设计不平衡。LongRAG 的做法是把 Wikipedia 处理成 4K-token 的 retrieval unit,显著减少检索单元总数,取得挺好的结果。
这背后的直觉非常实用,不是一定要把 chunk 切得更小,也可以反过来,把“召回单元”做大,把“证据抽取”放到后面。
# 传统
retrieval_units = split_into_256_token_chunks(docs)
# LongRAG 风格
retrieval_units = build_4k_semantic_units(docs) # 相关页面/段落打包成大单元
top_units = retriever.search(query, k=2)
# 再从大单元里做二次证据提取
evidence = extract_supporting_spans(top_units, query)这在落地上非常有帮助,因为如果你的场景是论文、技术文档、长报告、PRD,这种思路往往比死磕 256-token chunk 更靠谱,因为很多问题的证据本来就跨段落、跨小节。LongRAG 的价值不只是长,而是它逼着系统设计者重新想:召回阶段到底要返回“答案片段”,还是返回高质量证据,这里就足以体现一种工程和内容上的割裂感,召回到的内容跟回答的准确内容之间的不匹配性。
在内容难以解决的时候,结构的优化搬上来了,RAPTOR 是 2024 年很值得记住的一篇,因为它不再把语料库看成一堆平铺 chunk,而是递归摘要形成树结构,再在树上做 retrieval。论文报告在 QuALITY 上相对提升最高可达 20% 的绝对准确率。这非常重要,因为它解决的是多文档跨段落的内容整合问题,这是平铺 chunk没法解决的,至此,开始出现了垂类的专精设计,qa的chat系统这种局部事实问答的用平铺 chunk + 简单召回也能做的不错,而多模态文档问答,就必须要给系统一个能表达全局结构的检索对象,这也是 RAPTOR 和 GraphRAG 在 2024 年特别有启发性的地方。到 2025 年,研究已经进一步把问题往真实系统推进,开始讨论长上下文里 hard negatives 的破坏、测试时 compute 怎么分配、OCR 噪声如何级联污染整个 retrieval → generation 链路。
既然检索没法真正的确定和最终结果语义上的正确性,有相关工作就开始优化rerank了,我既然没法确定,那我就都搜罗过来,然后优化rerank不就好了嘛,这就有了rerankRAG。
RankRAG 很有意思,因为它直接指出一个现实问题:LLM 并不擅长阅读太多 context,而 dense embedding retrieval 也不一定能把最相关 chunk 放到最前面,所以单独靠 retriever 输出 top-k 还不够。RankRAG 提出用同一个指令调优的LLM同时做 context ranking 和 answer generation,它主要是被统一训练成两种能力,然后在推理时分两步调用:先 rerank,再 answer。这跟它的训练数据有关,简单来说就是构造数据集让ranking 和 generation 互相增强,这样做能让LLM回答问题需要学会识别哪些 context 真有用,而识别相关 context 又会反过来提升回答质量。

最小可落地版本甚至不需要训练 RankRAG 本体,先做 cross-encoder rerank 就已经能吃到大部分收益:
cands = hybrid_search(query, top_k=50)
pairs = [(query, d["text"]) for d in cands]
scores = cross_encoder.predict(pairs)
reranked = [doc for _, doc in sorted(zip(scores, cands), reverse=True)]
contexts = reranked[:6]这里真正关键的是:第一阶段追求高召回,第二阶段追求高精排。
不要指望一个单向量 ANN 检索同时把这两件事全做了。RankRAG 这类 2024 工作,本质上是在告诉大家:RAG 的排序目标需要更接近最终 answerability,而不是只接近 embedding similarity。
到了 2025 年,一个很明显的趋势是:大家开始系统性地研究 hard negatives、长上下文下的噪声扩散、测试时算力分配、文档解析误差 对 RAG 的伤害。也就是说,研究重点慢慢从“召回模块本身”转向“整个 retrieval pipeline 的鲁棒性”,这也是我觉得agent infra这个东西的开始,因为一旦涉及到E2E的优化,避免不了的就是各种pipeline的build和eval。
ICLR 2025 的 Long-Context LLMs Meet RAG 很值得看一遍。它明确说:随着 retrieved passages 数量增加,很多 long-context LLM 的输出质量会先上升,然后下降;论文把重要原因归结为 retrieved hard negatives 的破坏,如果我能吹这篇文章,我愿称之为context engineering的开篇鼻祖,我当初就是看到它才意识到context的重要性,这也基本上否决了scaling rerank-general的可能性,让它变成了一种数据处理手段。
这会把你的 pipeline 从:
docs = retriever.search(query, k=20)
answer = llm(query, docs)改成:
docs = retriever.search(query, k=20)
docs = rerank(docs, query)[:8]
docs = filter_irrelevant_or_redundant(docs, query)
answer = llm(query, docs)这个小改动的结论就是:RAG 的精度问题,常常不是 retriever 抓不到,而是 generator 没法在噪声环境里稳定读对。而这个小改动的文章提出一个很关键的视角:RAG 的 test-time compute 不只是“多拿几篇文档”,还包括 in-context learning、iterative prompting 等策略组合。论文报告在最优分配下,benchmark 上最高能比标准 RAG 带来 58.9% 的提升。这意味着一个成熟的 RAG 系统不应该只暴露 top_k 这一个旋钮,在多轮CoT中,每一轮都要控制token的数量,只取最有效的token,token管理很重要,所以工程上又要加码了:
def answer(query):
raw_docs = hybrid_search(query, top_k=40) # recall budget
ranked_docs = rerank(query, raw_docs)[:10] # ranking budget
support = select_diverse_supports(query, ranked_docs, max_tokens=6000)
draft = llm_reason(query, support, mode="draft") # reasoning budget
if low_confidence(draft):
refined_q = rewrite_from_failure(query, draft, support)
extra_docs = hybrid_search(refined_q, top_k=20)
support = merge_and_redo(support, extra_docs)
return llm_reason(query, support, mode="final")这就完了吗!其实没完,为什么呢,多模态平台中,效果不佳可能不是召回或者rerank,而是ocr。这时候你可能会理解为什么deepseek ocr能这么火热(当然deepseek本身流量也大),后来各种ocr都开始刷榜了。
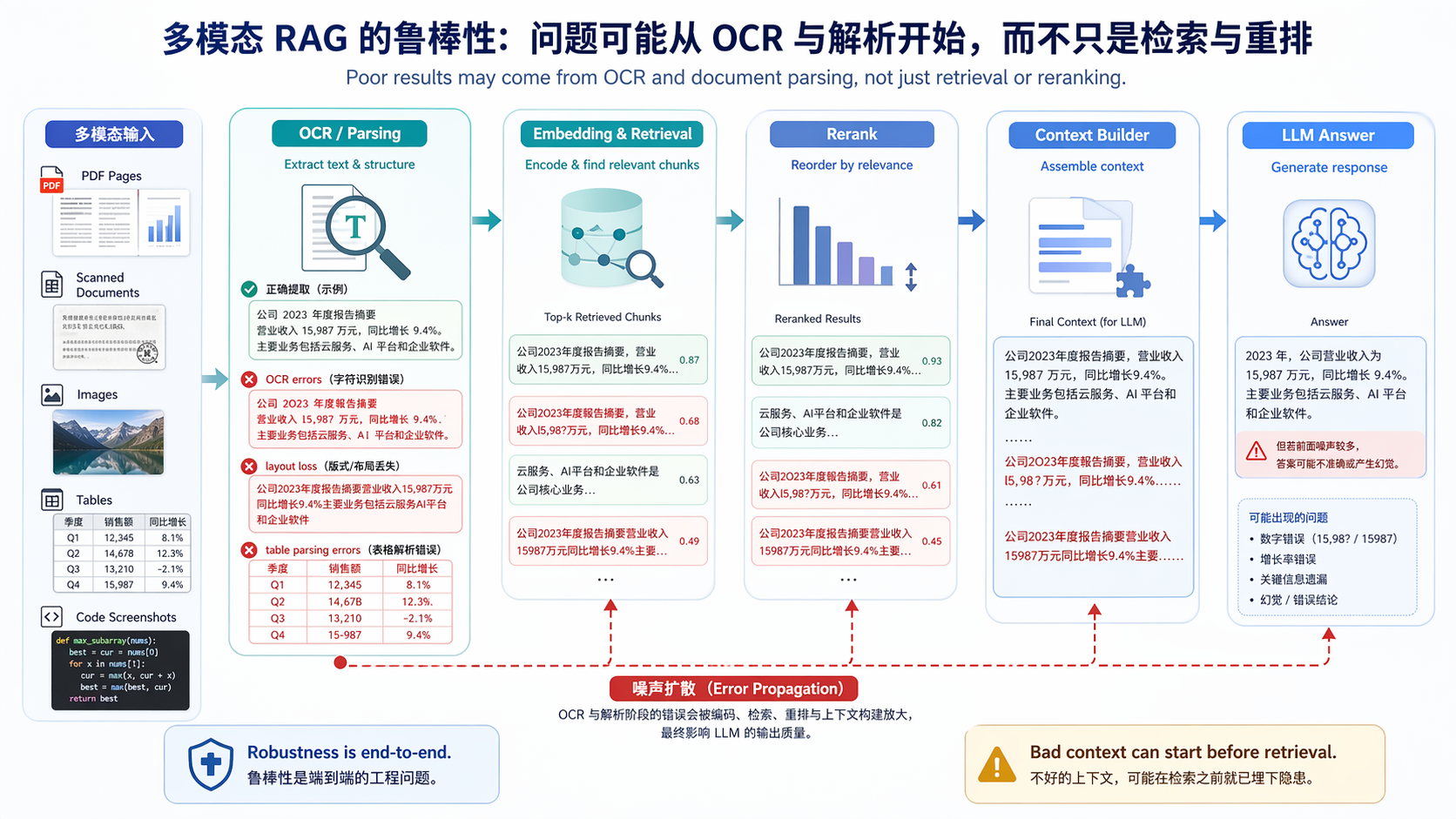
在功能稳定之后,我们不妨来聊聊架构,其实你发现了,我们长篇大论都在讨论rag,我由始到终都没提到过agent loop,为什么呢,因为在prompt engineering的时代,agent loop并不在重要,当时的微调手段比较单一,可用数据也不多,更重要的是刚开始投入并不大也没那么多卡,所以业界普遍都在做RAG,提升效果明显,所以这个时期,会出现workflow在RAGService中运行的情况:
# agentservice.py
class AgentService:
async def create() # 仅仅是作为LLM和agent的装配站
async def list_all()
async def get()
async def delete()
async def get_runs()
# ragservice.py
async def agentic_rag(prompt_context, agent, memory):
model = agent.get_model()
memory_context=memory._format_memories(memories)
messages=self._build_messages(prompt_context, memory_context)
for turn in range(max_turns):
LLMResult = self._llm.chat(model, messages)
answer = LLMResult.content
tools = LLMResult.tool_calls
if not result.tool_calls:
answer = result.content # 判断是否是最终答案
tool_log = [self._run_tool(tc, exec_map) for tc in result.tool_calls] # 不是答案就一定要用tools
messages.append(tool_log)
final: LLMResult = await self._llm.chat(
model, messages, temperature=temperature, web_search_enabled=web_search_on,
)
answer = final.content or "无法在限定轮次内完成回答。"这就很有意思了,agent loop居然不在agentservice中,而是在ragservice中,而且即便要装配skills、web search这种tools,写进agentic_rag()里也不会违和,这就很有意思了,我们抛开编码习惯和可能是之前写文件名没改之类的可能性来说,这是不是表达了一种agent可以被包在rag里的感觉,而这种感觉,我愿称之为纯正的prompt engineering,在这个体系里,rag是可以cover agent的。
所有在这个体系内修修改改的,都是prompt engineering相关的工作,因为本质上都是在修改给LLM的数据,就好比喂给客人的到底是龙虾鲍鱼还是白菜豆腐,原材料和厨师都至关重要。通过对tools的升级和限制,放大LLM的长处,让system更加的useful,减少LLM的错误,让system少一点useless,这就是我理解的prompt engineering。
不同上一节的最后才引出主题的useful or useless prompt engineering,我想开篇就告诉你,context engineering不止rag上对数据的清洗,也远远不止是infra上的信息流构建。
我觉得它更像是一种取舍和对齐的scaling艺术,是从预训练大模型的数据CAI开始、到web search数据的summary、到多模态memory的对齐检索和最后大模型输出,这其中每个参数的选择和限制都是取舍,这是一种由前到后、由后到前闭环的取舍艺术。
在这个模型和数据都爆炸scaling的时代,架构师们为了在各种垂类场景的各种稀奇古怪的prompt下系统都不会产出一堆shit可谓是煞费苦心(context rot),现在的垂类分化出来的系统设计的差异其实就是一种取舍,这种取舍可以从概率上简单表达为从不确定中找确定,而且是各方面都scaling的情况下去寻找确定性,这何尝不是一种艺术呢。
我们不妨挑点场景来分析,比如说常见的deep research系统,比如说gpt或者gemini的,它一般都会从网上搜集大量的资料,在memory没有外置成为独立模块的情况下,最常见的问题就是第一轮搜索拿到几十个来源,第二轮根据其中几个线索再展开,第三轮开始出现互相冲突的说法,第四轮已经忘了最初是为了验证哪个假设。
GPT Researcher之所以有启发,不是因为它会搜网页,人人都会调搜索 API,而是因为它把研究过程拆成了 research flow,并明确强调在这个 flow 中维护 memory 和 context。所以当研究的memory外挂成独立的模块,这时候应该有一份 ResearchState,里面至少包括目标、子问题、检索词、访问过的 URL、证据、排除原因、阶段性发现等等。这样主代理在做下一轮搜索时,不必重新读完所有网页,只需要读一份高密度研究状态。这个思路和 Anthropic 的 structured note-taking 非常一致。
from dataclasses import dataclass, field
@dataclass
class EvidenceNote:
source_id: str
claim: str
snippet: str
provenance: str
confidence: float
keep: bool = True
reason: str = ""
@dataclass
class ResearchState:
goal: str
subquestions: list[str] = field(default_factory=list)
search_queries: list[str] = field(default_factory=list)
visited_urls: set[str] = field(default_factory=set)
notes: list[EvidenceNote] = field(default_factory=list)
exclusions: list[dict] = field(default_factory=list)
interim_findings: list[str] = field(default_factory=list)
final_brief: str | None = None写完外挂的memory,然后agent loop 不再是搜一下 → 把网页塞回模型,而是搜一下 → 摘要成 note → 写入 research state → 再决定下一跳:
def research_loop(agent, state: ResearchState):
while not done(state):
query = agent.plan_next_query(state)
state.search_queries.append(query)
pages = web_search(query)
for page in pages:
if page.url in state.visited_urls:
continue
state.visited_urls.add(page.url)
note = agent.extract_evidence(page, state.goal, state.subquestions)
if note.keep:
state.notes.append(note)
else:
state.exclusions.append({
"source": page.url,
"reason": note.reason
})
state.interim_findings = agent.summarize_findings(state)
state.final_brief = agent.write_final_brief(state)
return state这里最关键的一步,是 extract_evidence 只产出面向任务的 note,而不是把网页原文继续传递。你可能会觉得,哦不就是一个summary嘛,这有啥的,但其实不然,这个summary可以串起这个小节的所有内容,因为summary是最cheap的effective and useful context engineering,为什么这么说呢?我们来看下一个场景:Math / Code agent。
这种Math / Code / 工具密集型任务的agent最大的问题是context被tools result淹没了,这没有什么好的办法,因为代码agent需要搜索代码、打开文件、运行测试、编译、读取日志、查看提交历史,而math agent则会频繁调用 REPL、符号工具、表格处理、绘图和计算模块,他们都不是原生的nlp,只能靠tools 来转译成自然语言表达,才能被感知,微软 2025 的 Code Researcher 也指出,系统代码修改需要研究 large codebase 和 massive commit history,说明这类代理的核心挑战之一就是如何在大量环境状态中保持上下文清洁。
这点在隐式或者半隐式的code agent和math agent中非常难以解决,常见的agent runtime架构中,当前的状态会让LLM决定下一步应该干什么,这就很重要了,我们需要维护一个memory的字段用来存concise_tool_summary ,这个字段是存储这次工具调用之后,agent 对任务世界的认识发生了什么变化?一个垃圾的summary可能会是:
测试失败,parser.py 有问题。这在决定下一轮要做啥根本没有意义,好的summary可能是:
新增失败定位到 tests/test_parser.py::test_nested_call。
当前 parse_args 在 nested call 场景下漏掉第二个参数 b。
最可疑代码位置是 parser.py:87 附近的参数递归解析逻辑。
这不是 import error,也不是环境依赖问题。这是一种高信息密度的压缩,注意这里发生了四件事:把日志压缩成任务相关事实,提取最可能的代码位置,识别失败类别,排除了无关方向。举个简单的例子,假如说我用这个:
from dataclasses import dataclass, field
from typing import Literal
@dataclass
class BeliefUpdate:
tool_name: str
new_facts: list[str] = field(default_factory=list)
suspected_locations: list[str] = field(default_factory=list)
ruled_out: list[str] = field(default_factory=list)
next_action_hint: str | None = None
confidence: float = 0.5然后每次工具调用之后,不是把 raw output 放进主上下文,而是更新 BeliefUpdate:
def summarize_pytest_output(raw: str) -> BeliefUpdate:
failures = extract_failed_tests(raw)
locations = extract_stack_locations(raw)
assertions = extract_assertions(raw)
return BeliefUpdate(
tool_name="pytest",
new_facts=[
f"Failed tests: {failures}",
f"Key assertions: {assertions}",
],
suspected_locations=locations[:5],
ruled_out=[
"dependency installation issue" if "ModuleNotFoundError" not in raw else ""
],
next_action_hint="Inspect the closest production code location in the stack trace.",
confidence=0.75,
)这样,每次输入的数据是有scheme的,在多轮的调度中,不会因为各次各自的输出格式不同出现莫名其妙的关注重点,导致context rot。这就完了吗,其实不然,还要加一个字段:error fingerprint 。这是加来干嘛的呢,在多轮的runtime推进过程中,除了max item的思考轮数计算来结束循环思考,还需要在中途让agent及时意识到已经进入了循环,这个非常的重要,如果没有 error_fingerprint,agent 很难知道自己其实在原地打转。
还完了吗,我们之前提到过,上下文一长,极其容易丢掉原来的目标,所以我们还要再来一个字段:artifact_pointer ,目的就是为了保住初心。因此一个简化的代码context agent,可以这么建模:
@dataclass
class CodeTaskContext:
goal: str
repo_map: dict
touched_files: list[str] = field(default_factory=list)
symbol_hits: list[dict] = field(default_factory=list)
commit_evidence: list[dict] = field(default_factory=list)
concise_tool_summaries: list[str] = field(default_factory=list)
error_fingerprints: list[str] = field(default_factory=list)
artifacts: list[str] = field(default_factory=list) # log paths, patch files, test reports然后给所有工具包一层统一的“清洗器”:
def normalize_tool_output(tool_name: str, raw_output: str) -> dict:
if tool_name == "pytest":
return {
"summary": summarize_test_failures(raw_output),
"fingerprints": extract_error_fingerprints(raw_output),
"artifact_path": save_raw_output(raw_output, suffix=".pytest.log")
}
if tool_name == "compiler":
return {
"summary": summarize_compile_errors(raw_output),
"fingerprints": extract_error_fingerprints(raw_output),
"artifact_path": save_raw_output(raw_output, suffix=".build.log")
}
return {
"summary": summarize_generic_output(raw_output),
"fingerprints": [],
"artifact_path": save_raw_output(raw_output, suffix=".txt")
}agent只读取 summary 和 fingerprints:
def update_code_context(ctx: CodeTaskContext, tool_name: str, raw_output: str):
pack = normalize_tool_output(tool_name, raw_output)
ctx.concise_tool_summaries.append(pack["summary"])
ctx.error_fingerprints.extend(pack["fingerprints"])
ctx.artifacts.append(pack["artifact_path"])这时候我们可以清晰的意识到一点,所有的tools都被降级了,从输出直接丢到context里做决策降级到必须summary和clear才能丢进memory,memory可能还要经过选择才会给context,这时候rag和tools都服务于agent loop,这就意味着从这里开始,ragservice不可能再包着agentservice了。
关于模型分化这个主题,姚顺雨认为,有两个大的感受,一个感受是 to C 和 to B 明显发生了分化,另一个感受就是垂直整合这条路和模型应用分层也出现了分化。
姚顺雨表示,我们今天用 ChatGPT 的时候,其实和去年用相比,对于大部分人、大部分时候,感受变化已经没有那么强烈了,因为它能力变强大部分人感受不到,大部分人大部分时候其实不需要用到这么强的智能。尤其在中国,更多像是使用一个搜索引擎的加强版,普通人很多时候也不知道该怎么样去用,去把它的智商激发出来。
由于单agent的不足和系统的高效性,自然而然就会让人想到多并发agent或者多agent,可以是一次运行多个一样的agent,也可以是一次运行多个不一样的agent。你可能会想,这不是废话吗,这有个锤子的区别呢?
哎,别急,听我说,我们找几个场景看看,比如说opencode或者claude code的subagent,它agent一样或者不一样其实没太区别,它能直接修改具体的代码,只要结果是对的,多agent之间有没有差异其实问题不大。再比如说kimi的多agent集群,我体验下来就是一个plan agent,构建多个子agent,赋予他们不同的人格和任务,让他们各自输出一个markdown就OK了,我们先不讨论效果,从架构上来说,他们也是各自产出各自的,但是LLM as judge、原生多模态agent和多阶段多角色agent等等,他们运行起来跟前面提到的系统没区别吗?
我觉得,越重的系统区别越大,为什么呢,其实是因为每个agent的scheme不一致导致的语义上的分歧,在长推理中,越长的推理越容易被各种scheme的规范输出给更改了原来的意思,导致彻底的context rot。所以问题不是他们长得像不像,而是这些 agent 到底是不是在同一个语义制度里工作。
像 subagent 去改代码、批量跑搜索、并发扫网页,这类任务的公共目标非常硬,此时 agent 更像 worker,谁来做、人格像不像、说话风格差一点,都无所谓,因为最后有外部世界的硬反馈兜底。Anthropic的文章里也说多agent的价值主要在 breadth-first exploration(真不如叫BFS算了,这群外国人造词有一手的,我一时间都不知道怎么翻译),也就是并行探索更大的搜索空间,这类场景下,agent 之间最重要的是任务切片和结果回收,而不是复杂的人格差异。
所谓“变重”,不是指 agent 变多,而是指系统开始同时依赖:长链规划、阶段状态切换、角色分工、跨 agent 汇总、以及中间产物的再次消费等等。到了这个层级,agent 之间的差异不再只是回答风格不同,而是解释世界的方式不同。MetaGPT 这种软件公司式系统本质上就是把不同角色嵌进不同 SOP,如果 PM agent 产出的需求文档天然偏抽象,architect agent 偏结构,engineer agent 偏可执行,那么它们之间的 handoff 已经不是在传原始语义,而是在传被角色过滤后的语义。这类过滤本身没错,问题在于一旦过滤规则不显式,后续 agent 很容易把角色化表达误当成原始事实。
呐,这下你理解我的看法了吧,回过头来看,kimi的agent集群就很类似同构并发的agent,看似不好,其实还可以,因为如果任务切的足够细,单agent的能力足够强,那么它多轮思考之后的输出结果也是非常不错的,而且从infra的角度看,如果按照数据结构的分析方法,agent逻辑集群和infra物理集群进行一一映射,这是非常优美且高效的结构,无法去评判这种技术到底是好是坏,因为这是非常优雅的取舍的艺术。
从这个角度再看 LLM-as-judge,就会发现它和前面那些多 agent 并发干活的系统压根不是一个东西。它的出现是因为SFT微调少了很多Ground Truth,只能靠这种方式类似于蒸馏来获得类似的答案,看起来也有多个 agent,也有分工,也有 aggregation,但它的关键不在分工完成任务,而在谁有资格定义任务是否完成。一旦你引入 judge,系统里就出现了一个新的 scheme 中心:它定义什么叫好答案、什么叫一致、什么叫充分、什么叫格式正确。问题是,judge 自己也有偏差。关于 LLM judge 的可靠性,近两年已经有越来越多的工作专门讨论位置偏差、自增强偏差、冗长度偏差,以及作为测量工具时的效度问题;2026 年还有工作直接把主题写成Stress Testing the Reliability of LLM Judges。也就是说,judge 不是一个中立的上帝视角,它只是另一个带有自己 scheme 的 agent。
难道异构协作的多agent就一无是处了吗?像 M-MAD 这种多维多 agent debate,用在机器翻译评估里是有价值的,因为它把 MQM 之类的评价标准拆成多个维度,让不同 agent 围绕不同维度讨论,最后再合成判断。类似地,2025 年也有工作把 multi-agent debate 用在 cultural alignment 上,希望用多个 agent 的争论提升跨文化判断的公平性。这里的关键点不是多 agent 一定更强,而是当评价标准本身可以拆成多个正交维度时,多 agent 才真正有意义。所以,我们可以得出结论多agent系统的本质,不是多个脑子一起想,而是多个context机制互相作用。
agent应该作为一个纠错的人
