该项目代码参考傅哥的课程,很有用的课程,请多多支持他。
reduce 规约求和是cuda中一个经典的问题,其本质是将输入的序列进行求和。
在CUDA的多线程中,我们清楚数据被分为一个一个的block中进行运行,每个block通过warp来并发32个线程进行运算。
所以将数据分割成一个一个block进行管理,然后每个block关注在自己的block的数据,那一个block里如何进行数据求和呢?
最简单就是从左到右咯,但是这样复杂度为O(n) ,这肯定是不让人满意的,一个线程由头执行到尾显然过于抽象。
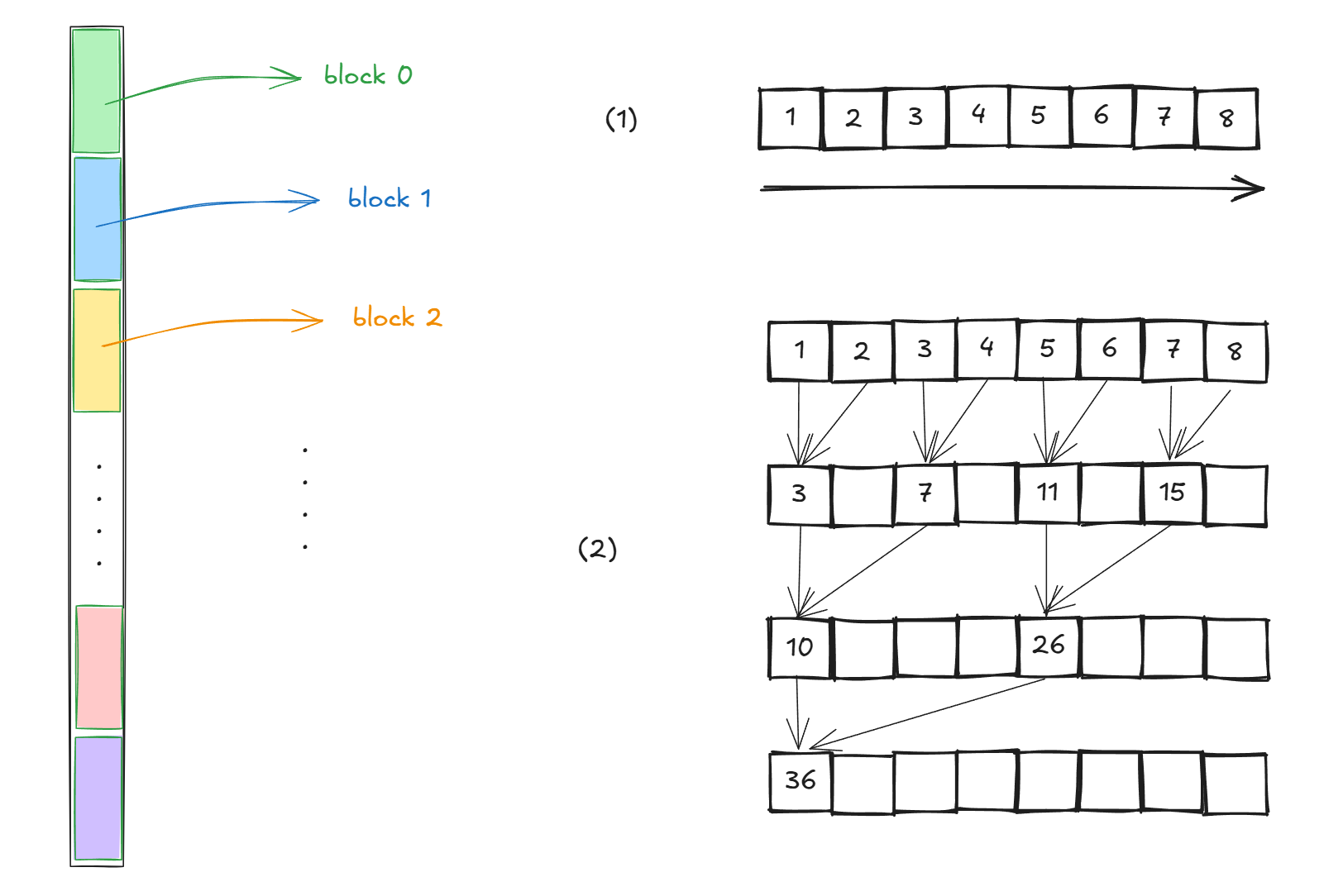
两两相加,每个两两相加放在一个线程里,这样如何呢?显然是非常棒的,从单线程优化到了多线程,原来O(n)的复杂度优化到了O(log_{2}n)。
当我们有了上面的理解,我们可以开始写代码啦,我们考虑一个1024 * 1024数组的加法,设定每个blocksize为1024,所以会有1024个block同时进行运算,请注意,我们每次写kernel都是面向block的,请切记。

#include <cuda_runtime.h>
#include <chrono> // 用于 CPU 计时
#include <iostream>
#include <numeric>
#include <vector>
const int BLOCK_SIZE = 1024;
const int N = 1024 * 1024; // 1M elements
int main() {
int num_blocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE; // 满足整除
std::vector<float> h_data(N);
for (int i = 0; i < N; i++) {
h_data[i] = 1.0f; // 简单起见,全部初始化为1.0
}
// -------------------------------
// CPU 计时开始
auto cpu_start = std::chrono::high_resolution_clock::now();
// CPU程序
float cpu_result = reduce_cpu(h_data);
auto cpu_end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> cpu_duration = cpu_end - cpu_start;
// CPU 计时结束
// -------------------------------
std::cout << "CPU result: " << cpu_result << std::endl;
std::cout << "CPU time: " << cpu_duration.count() << " ms" << std::endl;
float *d_data, *d_result;
float *d_final_result;
float gpu_result;
cudaMalloc(&d_data, N * sizeof(float));
cudaMalloc(&d_result, num_blocks * sizeof(float));
cudaMalloc(&d_final_result, 1 * sizeof(float));
cudaMemcpy(d_data, h_data.data(), N * sizeof(float), cudaMemcpyHostToDevice);
// -------------------------------
// GPU 计时开始 (CUDA Events)
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
// GPU程序
reduce_v0<<<num_blocks, BLOCK_SIZE>>>(d_data, d_result);
reduce_v0<<<1, num_blocks>>>(d_result, d_final_result);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
// GPU 计时结束
// -------------------------------
std::cout << "GPU kernel time: " << milliseconds << " ms" << std::endl;
cudaMemcpy(&gpu_result, d_final_result, sizeof(float),
cudaMemcpyDeviceToHost);
std::cout << "GPU result: " << gpu_result << std::endl;
if (abs(cpu_result - gpu_result) < 1e-5) {
std::cout << "Result verified successfully!" << std::endl;
} else {
std::cout << "Result verification failed!" << std::endl;
}
// 清理资源
cudaFree(d_data);
cudaFree(d_result);
cudaFree(d_final_result);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return 0;
}
CPU好说,就是从左到右加嘛:
// CPU验证函数
float reduce_cpu(const std::vector<float> &data) {
float sum = 0.0f;
for (float val : data) {
sum += val;
}
return sum;
}GPU使用block就要先想想咯,首先要明确一个block处理的数据范围,再想一个thread需要处理什么数据呢,如何把thread idx 和需要处理的数据的idx联系到一起呢?按照执行的顺序分出层次,最后每一层结束需要做归约:
首先需要处理的数据有32个
然后每个thread需要把相邻的两个数据相加,添加规约,这里的thread idx和前一个数的idx是匹配的,请谨记,threadIdx和dataIdx是有关联的,这里的关联是block内的threadIdx和global memory的dataIdx有关联。
然后把上一层thread输出的在相加,添加规约
重复上述过程若干,得到最后的结果
写回CPU
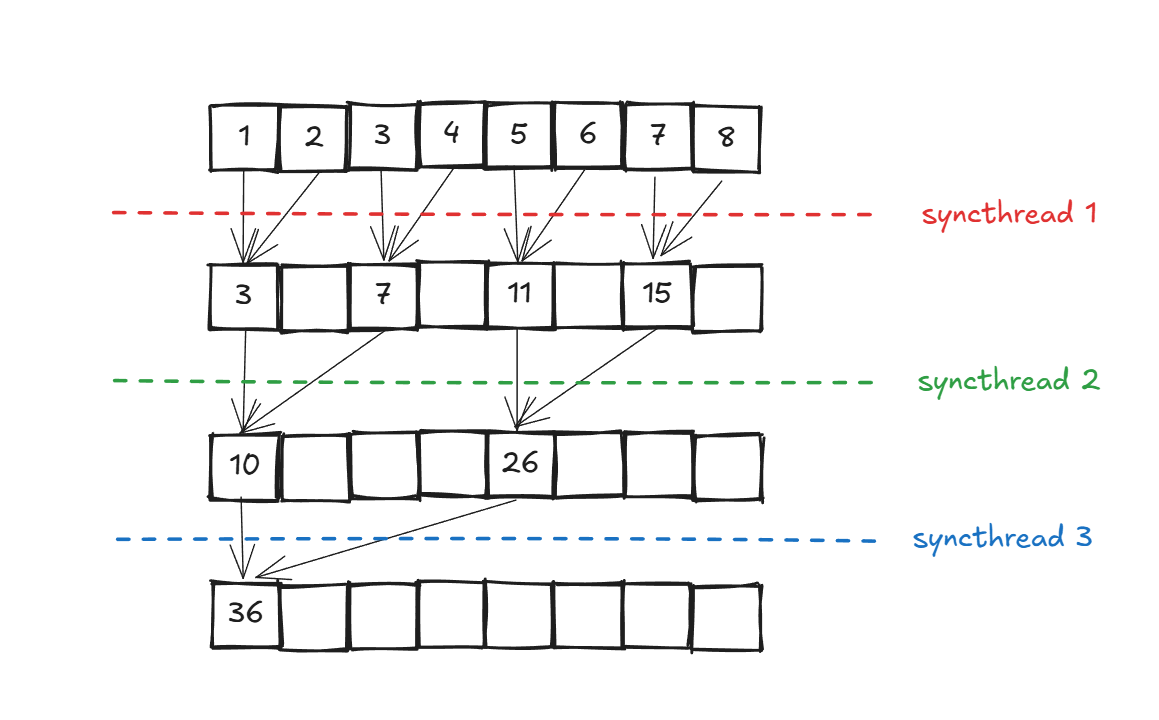
这下,这下明白了,也就是说,一共有4层,然后每一层执行加法的thread idx和前一个加数的idx是一样的:
第一层有thread 0 2 4 6需要执行加法
第二层有thread 0 4 需要执行加法
最后一层有thread 0 需要执行加法
这里有三层,每一层需要执行的thread idx是有规律的,请铭记,我们写的kernel是一个block内threadidx和input数据idx的计算过程,每个threadidx都会执行一个kernel内的代码。
有一个小技巧,当我们看到了__syncthreads()的时候,请把前后的代码隔开来看,说明前面的代码具有并行性,因为其含义就是只有一个kernel内所有thread都执行到这一步,才会继续往下执行。
__global__ void reduce_v0(float *d_input, float *d_output)
{
unsigned int tid = threadIdx.x;
unsigned int bid = blockIdx.x;
unsigned int gdx = bid * blockDim.x + tid;
float *start_input = d_input + blockDim.x * bid;
for (int i = 1; i < blockDim.x; i *= 2)
{
// 第一层执行的threadidx 0 2 4 6
// 第二层执行的threadidx 0 4
// 第三层执行的threadidx 0
if (tid % (i * 2) == 0)
{
start_input[tid] += start_input[tid + i];
}
__syncthreads();
}
if (tid == 0)
d_output[blockIdx.x] = start_input[0];
}好了,运行结果如何呢?
CPU result: 1.04858e+06
CPU time: 5.72837 ms
GPU kernel time: 0.969824 ms
GPU result: 1.04858e+06
Result verified successfully!这里我们开了两个kernel,一个处理
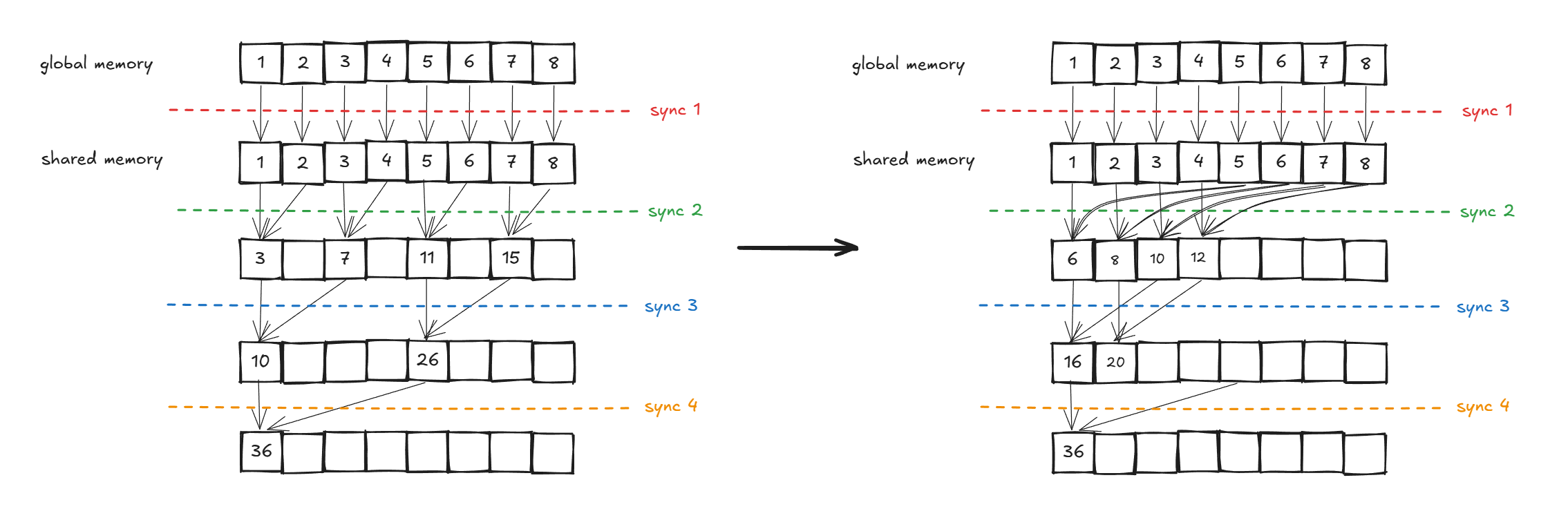
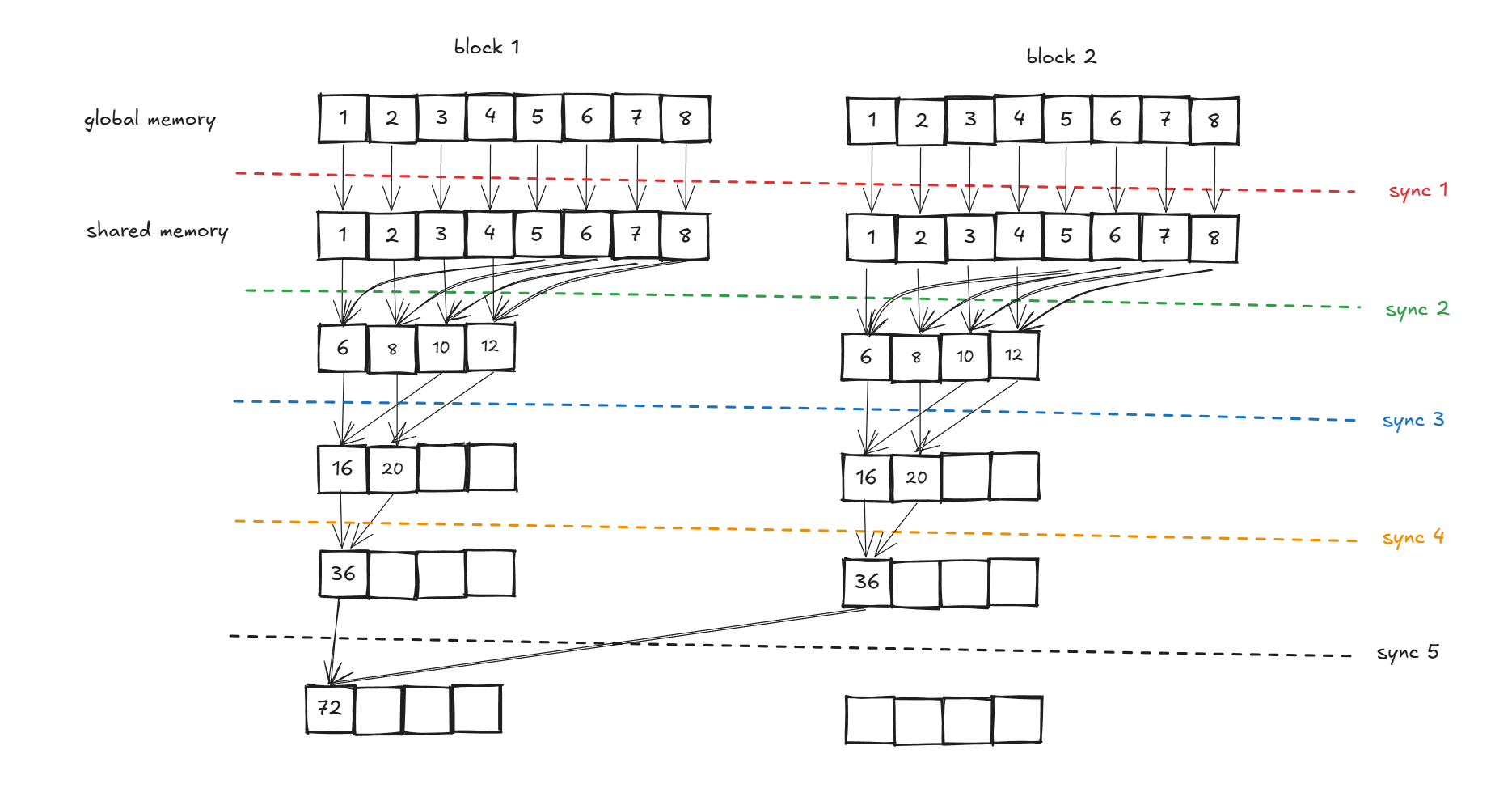
但是真的是那么简单吗?深度思考一步,如果说在block层面也有同步呢?如下图:

为什么block1 和block2都是红色呢?是的,他们是可以同时执行的,但是block 3是需要等待block1和block2先执行完再执行的,这就意味着这里有分层,这里挖个坑,后面会补,这里其实应用已知知识已经可以完成了,大伙不防想想解决。
两两相加的最简单的优化已经说清楚了,接下来我们将省略掉多余的构造数据啊,测试啊之类的,只专注于kernel的优化。从下面的优化开始,我们将使用cuda的特性进行优化。
第一个优化是共享内存(share memory),在第一节中,我们看到了一个SM内有一块256KB的L1 Share memory低延迟的内存池,这个share memory是整个SM四个swarp执行单元都能共享的,是实现线程间高效通信与协作的关键资源。

与全局显存(Global Memory)相比,共享显存访问延迟大约低 20~30 倍,带宽则高出约 10 倍。现阶段所有的优化几乎都建立在share memory上,后面默认使用share memory的优化。
在 CUDA 中,共享显存可以根据需求静态分配或动态分配。这里常用的一种方法是,在执行kernel的时候,block将所需的数据移动到share memory中,然后再执行kernel进行运算。
由于众所都周知的block内threadIdx和InputIdx是有关联的,所以搬运数据也可以通过同步搬运的方式来减少时延。
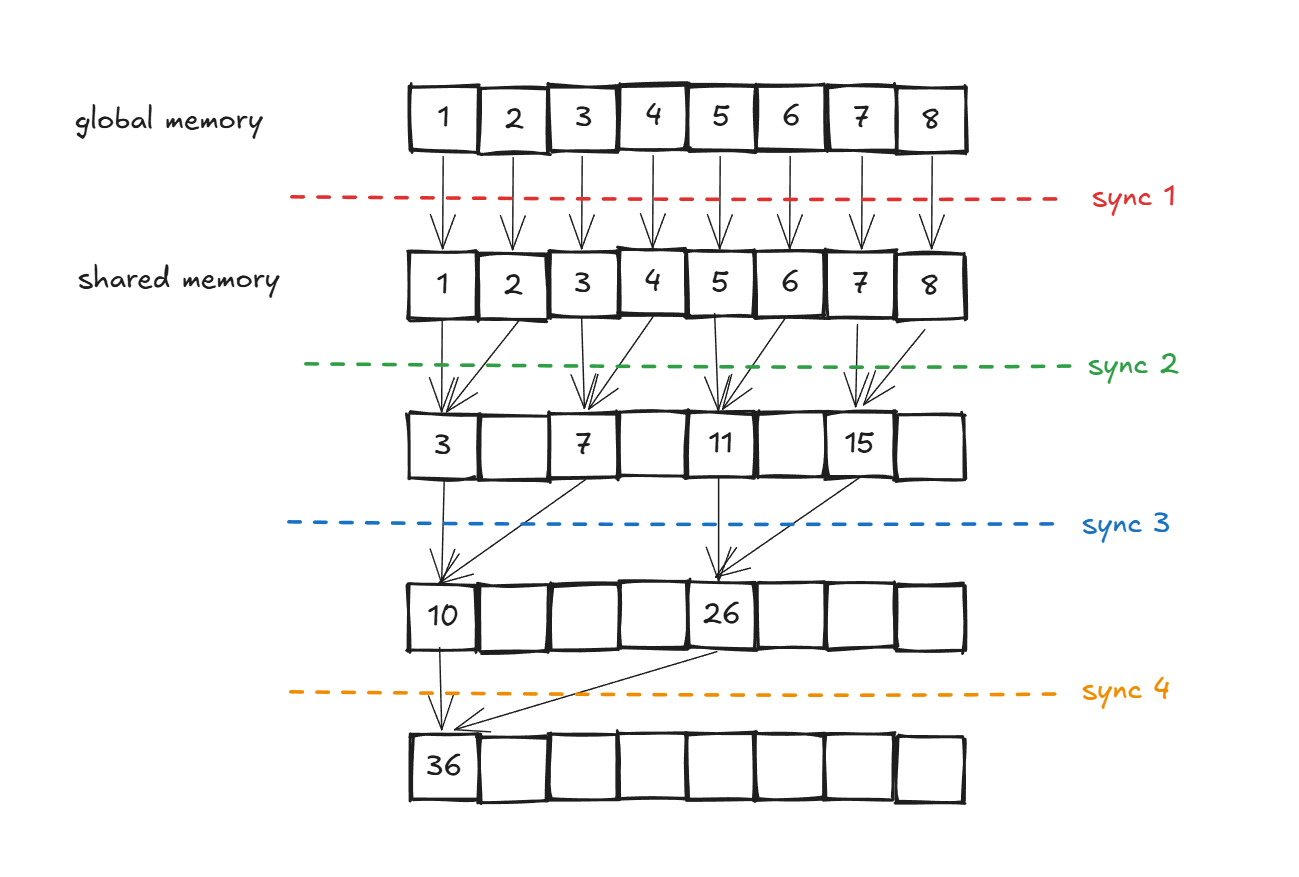
需要注意的是,当global memory的input搬运到shared memory中,原本的全局访问变成了block内的访问,是不需要通过blockDim.x*blockIdx.x去计算起始位置在哪的。
__global__ void reduce_v0(float *d_input, float *d_output)
{
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int bid = blockIdx.x;
unsigned int gdx = bid * blockDim.x + tid; // global thread index
//float *start_input = d_input + blockDim.x * bid; // 计算global input中的起始位置
if(gdx < N)
{
sdata[tid] = d_input[gdx]; // 将全局数据搬运到block中的shared memory
}
else
{
sdata[tid] = 0.0f; // 如果global thread index超出范围,则初始化为0
}
__syncthreads(); // 同步保证数据都搬运到shared memory
for (int i = 1; i < blockDim.x; i *= 2)
{
// 第一层执行的threadidx 0 2 4 6
// 第二层执行的threadidx 0 4
// 第三层执行的threadidx 0
if (tid % (i * 2) == 0)
{
sdata[tid] += sdata[tid + i];
}
__syncthreads();
}
if (tid == 0)
d_output[blockIdx.x] = sdata[0];
}输出对比如下:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ ./build/reduce-v1
CPU result: 1.04858e+06
CPU time: 5.4419 ms
GPU kernel time: 0.886144 ms
GPU result: 1.04858e+06
Result verified successfully!
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ ./build/reduce-v0
CPU result: 1.04858e+06
CPU time: 5.23072 ms
GPU kernel time: 1.11389 ms
GPU result: 1.04858e+06
Result verified successfully!v1相比v0提升了0.227s,相比v0提升了20%的性能,是非常不错的优化,故此往后每次默认都是shared memory,而且能更好的锁定所计算的数据范围。此时可以用nsight computer看到对应的shared memory实际执行了多少条指令。
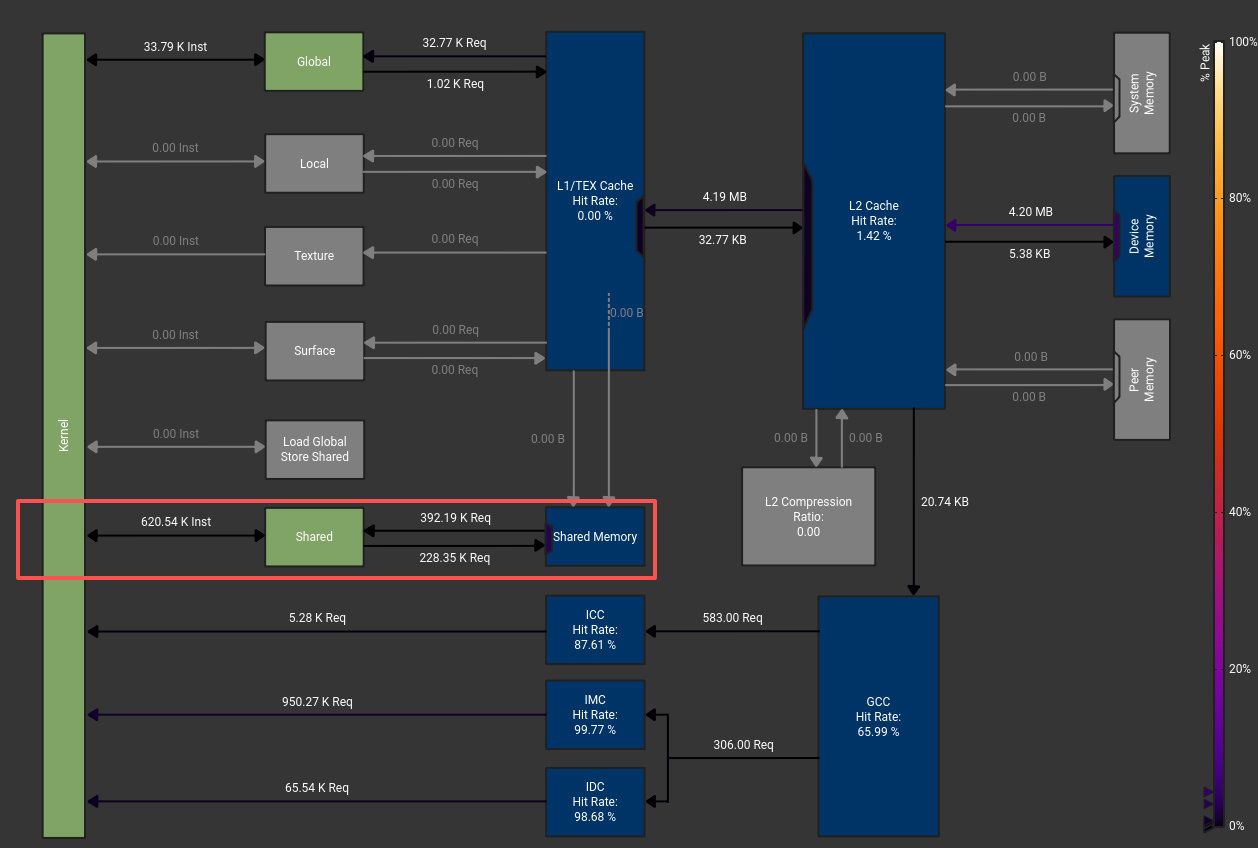
我们对cuda kernel进行优化,除了shared memory这个必要的优化,就是对每次并发的warp,我们希望每个线程尽可能的努力工作,我愿称之为线程农场主思想。
那么我们开始看之前的执行过程,发现每次运行的时候,相邻的两个线程只有一个是在运行的,那不行,那肯定要归并到一起。那一个block多出来的四个线程咋办呢?那就把隔壁的原来block的数据拿过来一起算了!这样就可以剩下来隔壁的八个线程,秒啊,太妙了!
好,当我们开始摩拳擦掌开始写代码,开始思考第一步时,发现了一个问题:我们需不需要开两倍BLOCKSIZE的shared memory呢?
你肯定会说,啊,你都说了,肯定可以,但是我们在不知道的情况下,我们一定要思考如何优化到极致,能不能,,,,不开呢?
观察上图,我们发现多出来的一倍主要是隔壁原来的block的部分,然后下一步才把隔壁的数据拿过来加在一起,那我能不能,,,在复制过去之前,就把它加上去呢!天才,绝对是天才,那上面的图就优化成下图了:
 噢太棒了,让我们开始写
噢太棒了,让我们开始写kernel把,开了一个BLOCKSIZE的shared memory,然后要写搬运了,怎么写呢?
现在每个block管的数据范围是之前的两倍,也就是blockDim.x是之前的两倍,那么起始位置已经不一样了,然后thread的数量还是一样的,这样我们就能处理好运算了:
__shared__ float sdata[BLOCK_SIZE];
unsigned int tid = threadIdx.x;
unsigned int bid = blockIdx.x;
unsigned int gdx = bid * blockDim.x * 2 + tid; // global thread index
//float *start_input = d_input + blockDim.x * bid; // 计算global input中的起始位置
if(gdx < N)
{
sdata[tid] = d_input[gdx] + d_input[gdx + blockDim.x]; // 将全局数据搬运到block中的shared memory
}
else
{
sdata[tid] = 0.0f; // 如果global thread index超出范围,则初始化为0
}
__syncthreads(); // 同步保证数据都搬运到shared memoryOK,那下面是一样的吗?是的,是一样的,也不用动,那就可以跑了。。。。吗?哎,为什么有疑惑呢?我们先跑起来看看:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ ./build/reduce-v2
CPU result: 1.04858e+06
CPU time: 5.18984 ms
GPU kernel time: 1.00202 ms
GPU result: 1.04858e+06
Result verified successfully!噢?似乎不太妙啊,好像只降低了0.1s哎?这对吗,这显然不对。这是为什么呢?
是的,聪明的你确实想到了,我们上面的方法是把隔壁的block的数字给求和求完了,但是我们的block_num没有减少,也就是说我们还是开了那么多block,这怪不得优化不对劲呢!此时我们修改为/:
int num_blocks = ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) / 2;然后我们再跑一次:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ ./build/reduce-v2
CPU result: 1.04858e+06
CPU time: 5.61895 ms
GPU kernel time: 0.628096 ms
GPU result: 1.04858e+06
Result verified successfully!噢这太棒了,0.628s,多么美妙的数字,比起v1提升了29.1%,而比v0足足提升了44%!这下明白了,shared memory和减少block_num提高线程利用率是如此的重要,这将会是我们所有优化的核心宗旨。
