CUDA是什么
cuda是一种gpu编程组件,是一种原生支持GPU软硬件的架构,使得开发者可以直接在 GPU 上编写和执行通用计算程序。
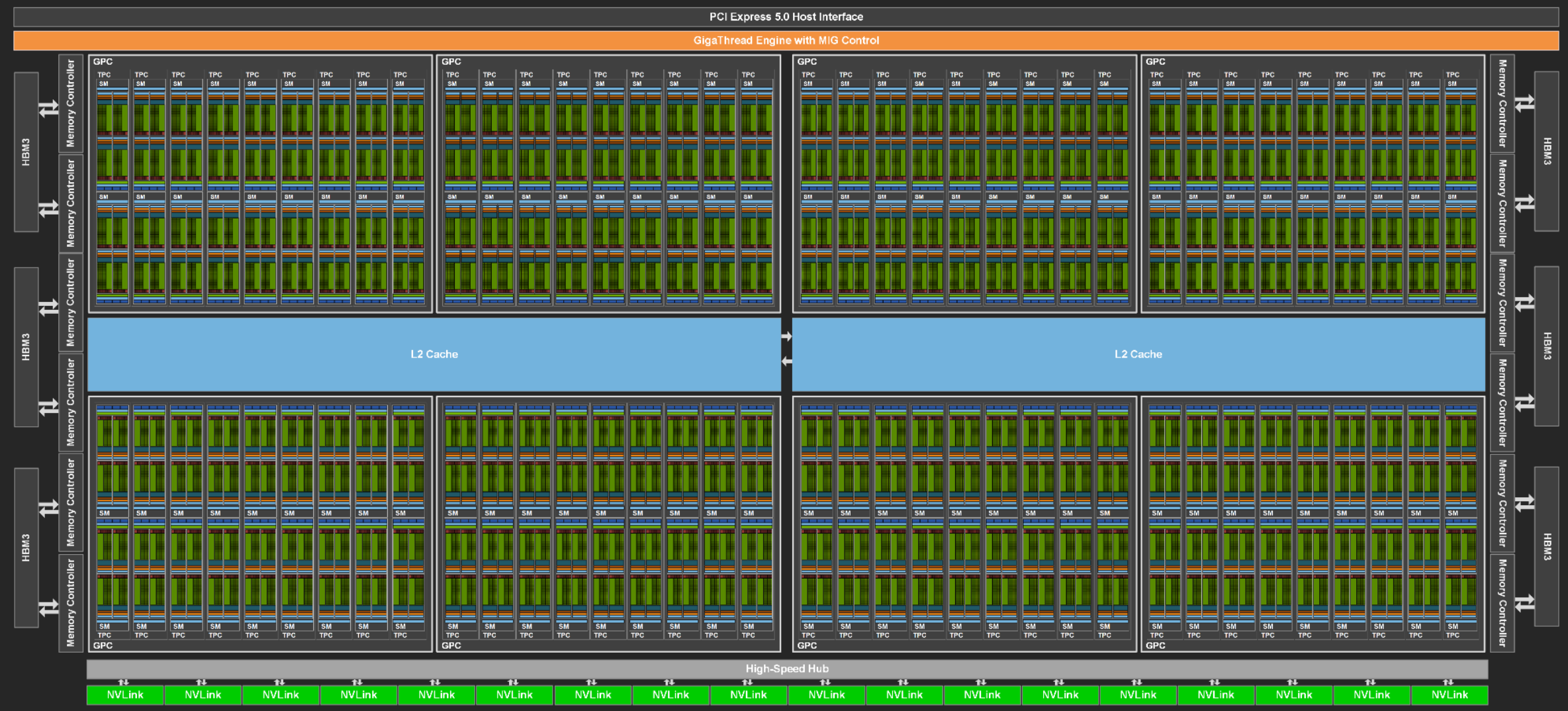
上图是H100白皮书中,H100 GPU带满了144个SM的架构图

上图是H100中,1个SM的架构图
由此,我们可以高屋建瓴的看懂GPU,这里不雕琢细节,只直白的说明白GPU怎么工作的:
PCIE 就是负责数据从显卡和主板之间进出的数据传输协议,理解为传递数据的就对了
使用一个Giga Thread Engine来管理所有正在进行的工作,将大的拆小,然后分给不同的SM进行计算
所有的Cache都是为了快速命中数据,Share Memory都是为了共享数据,都是存数据的地方,越往里Cache的速度越快
GPU被划分为多个SM(Stream Multiprocessor,流多处理器),SM是真正负责计算的东西
每个SM有:
Instruction cache就是负责存储指令的,告诉SM要执行什么命令
Warp Scheduler(线程束调度器)就是并行发射指令给执行单元进行运算的,每次发射多组(比如说32线程为1组)的任务给空闲的单元。
Dispatch Unit 分配单元则将这些线程的指令分配到有限的任务执行单元
Register File(寄存器文件)存临时变量(比如计算过程中的中间结果)
四个四代Tensor core运算核心
INT32 / FP32 / FP64 / Tensor Core 这些是SM里的“工人”,负责不同类型的计算。
INT32:处理整数(比如1、2、3)。
FP32/FP64:处理小数(比如3.14、2.718),FP64更精确但更慢。
Tensor Core(第四代):专门做AI计算的“超级工人”,比如矩阵乘法(深度学习核心运算),速度比普通工人快几十倍。
LDI / ST / SFU / Tex 这些是SM的“辅助工具”
LDI(Load/Store单元)负责拿取和存储数据
SFU(特殊功能单元)负责执行如三角、开平方等特殊操作
Tex(纹理单元)原本用于图形处理,现在也有骚操作
Tensor Memory Accelerator 专门帮Tensor Core快速搬运数据
cuda是一个直接控制GPU运算的语言,当前大模型训练需要一大堆的GPU,而 CUDA 正是让这堆 GPU 协同工作的"通用语言",无论是训练还是推理,CUDA无处不在。

其中CUDA lib中会有一些高级库,如线性代数的库CUBLAS,快速傅里叶的库CUFFT等
CUDA Runtime API 包含帮助程序员管理设备内存、调度并行任务和进行数据传输等操作
CUDA Driver API 是CUDA 与GPU 沟通的驱动级底层API。
#include <cuda_runtime.h>
#include <iostream>
// 这段代码是在gpu当中执行的
__global__ void hello_world(void) {
printf("thread idx: %d\n", threadIdx.x);
if (threadIdx.x == 0) {
printf("GPU: Hello world!\n");
}
}
int main(int argc, char **argv) {
printf("CPU: Hello world!\n");
hello_world<<<1, 10>>>();
cudaDeviceSynchronize(); // cpu要等待gpu执行结束
if (cudaGetLastError() != cudaSuccess) {
std::cerr << "CUDA error: " << cudaGetErrorString(cudaGetLastError())
<< std::endl;
return 1;
} else {
std::cout << "GPU: Hello world finished!" << std::endl;
}
std::cout << "CPU: Hello world finished!" << std::endl;
return 0;
}执行以下命令:
nvcc -g -G -O0 -o hello hello_world.cu
./hello
写过无输出hello world的各位其实也能看大概懂这里发生了什么,这里就是使用cuda"并行"了10个线程的数据,很快的就输出完了。
聪明的你肯定发现了,并行打了个双引号,这是为什么呢?聪明的你肯定又发现了这里的输出结果居然不是"并行"的,因为并行必然带来的是输出的顺序不一,聪明的你肯定又想到了,如果我拉大并行的thead呢?
我 们将上述代码中的线程数拉到100,也就是hello_world<<<1, 100>>>();,跑一边,执行结果如下:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_code/course1$ nvcc -g -G -O0 -o hello hello_world.cu
nvcc warning : Support for offline compilation for architectures prior to '<compute/sm/lto>_75' will be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
(base) moyu@DESKTOP-5C0FGMS:~/cuda_code/course1$ ./hello
CPU: Hello world!
thread idx: 96
thread idx: 97
thread idx: 98
thread idx: 99
thread idx: 0
thread idx: 1
thread idx: 2
thread idx: 3
thread idx: 4
thread idx: 5
thread idx: 6
thread idx: 7
thread idx: 8
thread idx: 9
thread idx: 10
thread idx: 11
thread idx: 12
thread idx: 13
thread idx: 14
thread idx: 15
thread idx: 16
thread idx: 17
thread idx: 18
thread idx: 19
thread idx: 20
thread idx: 21
thread idx: 22
thread idx: 23
thread idx: 24
thread idx: 25
thread idx: 26
thread idx: 27
thread idx: 28
thread idx: 29
thread idx: 30
thread idx: 31
thread idx: 32
thread idx: 33
thread idx: 34
thread idx: 35
thread idx: 36
thread idx: 37
thread idx: 38
thread idx: 39
thread idx: 40
thread idx: 41
thread idx: 42
thread idx: 43
thread idx: 44
thread idx: 45
thread idx: 46
thread idx: 47
thread idx: 48
thread idx: 49
thread idx: 50
thread idx: 51
thread idx: 52
thread idx: 53
thread idx: 54
thread idx: 55
thread idx: 56
thread idx: 57
thread idx: 58
thread idx: 59
thread idx: 60
thread idx: 61
thread idx: 62
thread idx: 63
thread idx: 64
thread idx: 65
thread idx: 66
thread idx: 67
thread idx: 68
thread idx: 69
thread idx: 70
thread idx: 71
thread idx: 72
thread idx: 73
thread idx: 74
thread idx: 75
thread idx: 76
thread idx: 77
thread idx: 78
thread idx: 79
thread idx: 80
thread idx: 81
thread idx: 82
thread idx: 83
thread idx: 84
thread idx: 85
thread idx: 86
thread idx: 87
thread idx: 88
thread idx: 89
thread idx: 90
thread idx: 91
thread idx: 92
thread idx: 93
thread idx: 94
thread idx: 95
GPU: Hello world!
GPU: Hello world finished!
CPU: Hello world finished!
布豪,这对吗!这不对吧!怎么会是这样的!
莫慌,少年,你懂的,并行的世界,一如既往的疯癫!
这是因为CUDA 的线程在硬件里是按"32 线程一组"的 Warp来调度的,而同一个 Warp里的线程并不是必须按 0-31、32-63 这种顺序执行。当 block 里有 100 个线程时,会被切成 4 个 Warp:
Warp 0:threadIdx.x 0-31
Warp 1:threadIdx.x 32-63
Warp 2:threadIdx.x 64-95
Warp 3:threadIdx.x 96-99(只有 4 个线程有效)
这 4 个 Warp 谁先拿到 Warp Scheduler 的"发令枪",谁就先把结果打印出来。从输出结果来看,Warp 3(96-99)抢到了第一个调度机会,于是 96-99 先出现在屏幕上;接着才是 Warp 0、1、2 依次打印 0-95。
那么在执行一次呢!输出如下:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_code/course1$ ./hello
CPU: Hello world!
thread idx: 96
thread idx: 97
thread idx: 98
thread idx: 99
thread idx: 64
thread idx: 65
thread idx: 66
thread idx: 67
thread idx: 68
thread idx: 69
thread idx: 70
thread idx: 71
thread idx: 72
thread idx: 73
thread idx: 74
thread idx: 75
thread idx: 76
thread idx: 77
thread idx: 78
thread idx: 79
thread idx: 80
thread idx: 81
thread idx: 82
thread idx: 83
thread idx: 84
thread idx: 85
thread idx: 86
thread idx: 87
thread idx: 88
thread idx: 89
thread idx: 90
thread idx: 91
thread idx: 92
thread idx: 93
thread idx: 94
thread idx: 95
thread idx: 0
thread idx: 1
thread idx: 2
thread idx: 3
thread idx: 4
thread idx: 5
thread idx: 6
thread idx: 7
thread idx: 8
thread idx: 9
thread idx: 10
thread idx: 11
thread idx: 12
thread idx: 13
thread idx: 14
thread idx: 15
thread idx: 16
thread idx: 17
thread idx: 18
thread idx: 19
thread idx: 20
thread idx: 21
thread idx: 22
thread idx: 23
thread idx: 24
thread idx: 25
thread idx: 26
thread idx: 27
thread idx: 28
thread idx: 29
thread idx: 30
thread idx: 31
thread idx: 32
thread idx: 33
thread idx: 34
thread idx: 35
thread idx: 36
thread idx: 37
thread idx: 38
thread idx: 39
thread idx: 40
thread idx: 41
thread idx: 42
thread idx: 43
thread idx: 44
thread idx: 45
thread idx: 46
thread idx: 47
thread idx: 48
thread idx: 49
thread idx: 50
thread idx: 51
thread idx: 52
thread idx: 53
thread idx: 54
thread idx: 55
thread idx: 56
thread idx: 57
thread idx: 58
thread idx: 59
thread idx: 60
thread idx: 61
thread idx: 62
thread idx: 63
GPU: Hello world!
GPU: Hello world finished!
CPU: Hello world finished!
这时候聪明的你可能发现了什么,你会发现这个并行,还是需要"并行",这是为什么呢?这时聪明的你发现了:
这个"并行"只是一个SM里的并行,并不是多个SM的并行。
是的,真正的并行,是多个SM的并行,这是为什么呢?这就要说到我们的设定了:
hello_world<<<1, 100>>>()
kernel<<<gridDim, blockDim>>>
其中:
gridDim表示一个grid有几个block
blockDim表示一个block有几个thread
两者相乘就是需要并发的thread数量
根据上面的例子,就是有一个block,里面有100个thread,若一个warp并发32threads,则block里的Warp Scheduler会并发四个warp,哪个warp先执行就先输出
cuda kernel function是面向block的函数,每个block里面的thread都会一起执行kernel函数,根据每个线程的threadIdx和dataIdx的匹配进行运算,最后把结果放到output指向的global memory中。
举一个简单的例子,假如说一个GPU就是一个工厂,你写的kernel就是给工厂分配工人,这时候你做出了如下的配置:
__global__ void add(float* a, float* b, float* c) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
dim3 gridDim(1000, 1, 1); // 1000 条生产线
dim3 blockDim(256, 1, 1); // 每条线 256 名工人
add<<<gridDim, blockDim>>>(d_a, d_b, d_c);
1000×256 = 256 000 名工人。
GigaThread Engine 把 1000 条生产线排给若干 SM。
每条生产线(256 线程)= 8 个 Warp(32 人小队)。
这 8 个小队在 Warp Scheduler 的指挥下,轮流去 CUDA Core 做加法,去 LD/ST 单元 读/写 a[i]、b[i]、c[i]。
如果 a、b、c 的数据已经在 L2 Cache(大仓库),就直接拿;不在就去显存搬。
拓展一下,相信你也注意到了,上面的kernel配置grid和block的维度是三维,这如何理解呢?
还是以工厂为例子:
gridDim(x, y, z) = 工厂园区的布局,每个维度代表不同方向的厂房排列
blockDim(x, y, z) = 每个车间内工人的排列方式,每个车间有自己的工具间(shared memory),车间内工人可以快速交流协作
每个工人有自己的工号(threadIdx),工人知道自己在哪个车间(blockIdx)
以下面的为例
// 3D配置:2x2x2的立体车间,每个车间2x2x2的工人
dim3 grid3d(2, 2, 2); // 2x2x2立体车间
dim3 block3d(2, 2, 2); // 每个车间2x2x2工人立体排列
volume_process_3d<<<grid3d, block3d>>>(d_volume, width, height, depth);注意是上下摆放的
工厂:
上层: [车间1,1,1][车间1,2,1]
[车间2,1,1][车间2,2,1]
下层: [车间1,1,2][车间1,2,2]
[车间2,1,2][车间2,2,2]
线程总数 = gridDim.x × gridDim.y × gridDim.z × blockDim.x × blockDim.y × blockDim.z
每个线程的全局ID = blockIdx × blockDim + threadIdx
同一block内的线程可以通过shared memory快速通信
不同block的线程只能通过global memory通信
至此,恭喜你,成功入门CUDA
(待补充)
矩阵乘法(Gemm):matmul、batch norm、等
Silding window类:conv2d、conv3d、maxpool等
Reduce类:Softmax类
Elemenwise类:gelu、copy_if
Fused类:Matmul&Bais&Relu等
Scan类:prefixsum、cumsum等
Sort类:mergesort
坐标变换类:concat、transpose等
