收集我和我小伙伴互相问的八股问题,里面有gemini deep search的回答,望周知。
GELU: 高斯误差线性单元
ReLU: 修正线性单元
Swish (β=1.0): 标准Swish函数
Swish (β=0.5): 低β值的Swish函数
SwishLU: Swish + Linear Unit组合
其函数代码如下:
def gelu(x):
"""GELU激活函数"""
return 0.5 * x * (1 + erf(x / np.sqrt(2)))
def relu(x):
"""ReLU激活函数"""
return np.maximum(0, x)
def swish(x, beta=1.0):
"""Swish激活函数 (SiLU when beta=1)"""
return x / (1 + np.exp(-beta * x))
def swishlu(x, beta=1.0):
"""SwishLU激活函数 (Swish + Linear Unit)"""
# SwishLU: max(Swish(x), x)
swish_val = swish(x, beta)
return np.maximum(swish_val, x)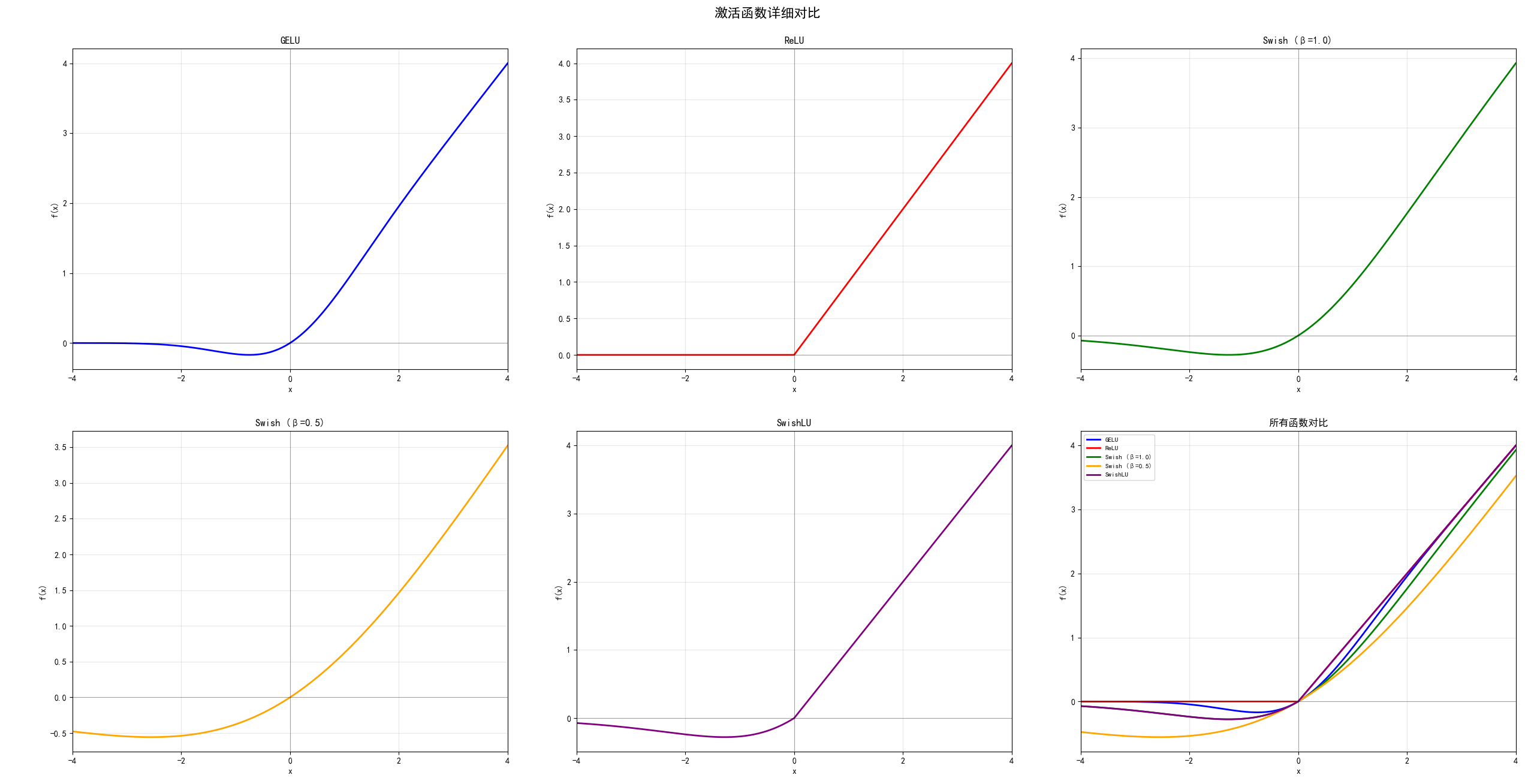
ReLU (修正线性单元)
优点:计算简单、速度快、解决梯度消失、稀疏激活
缺点:"死亡ReLU"问题、非对称、在x=0处不可导
GELU (高斯误差线性单元)
优点:光滑连续可导、基于概率理论、Transformer中表现优异
缺点:计算复杂度高、训练速度较慢
Swish (β=1.0)
优点:光滑、非单调、无上界、自门控机制、梯度流动好
缺点:计算复杂度高、参数需调优、可能梯度爆炸
Swish (β=0.5)
优点:更加平滑、负值激活温和、数值稳定性更好
缺点:激活强度较弱、深度网络表现可能不如β=1
SwishLU (实验性)
优点:结合Swish光滑性和线性增长、避免梯度消失
缺点:新颖函数、理论研究不足、实际应用验证不充分
这也是为什么llama选择了
该转变是由Deepseek 的V2 从softmax转变成了Deepseek V3的sigmoid函数,首先来看一下架构的对比:
V2版。路由专家数: 每个 MoE Layer 包含 162 个专家,其中 2 个是共享专家,160 个是路由专家,每个 Token 激活 2+6=8 个专家。共 236B 参数量,每个 Token 激活 21B 参数。
V3版。路由专家数: 256, 激活专家数:8个, 模型总参数671B,激活参数37B
原因可能如下:
V3相对于V2的路由专家数增加了近100个,softmax要在内部对所有维度的值做归一化处理。因为所有维度加和要等于1,所以维度越大,每个维度值理论上分配的值就越小,导致激活更不准确,计算误差会加大。而且DeepSeek-V2时已经采用了FP32的精度。这样在选取 TopK 个最大值时,对更小的小数位会更敏感,导致数据区分度不高,维度越大,问题越严重。
Sigmoid函数的值域更宽,更适合高维度操作。Sigmoid函数的是对每个专家分别计算一个 [0,1] 的打分,它并是不随专家维度变化而变化,理论上计算的打分值域更宽,区分度更高。
在算子来说,softmax需要遍历,而sigmoid不需要
参考文章里面还有梯度下降的视角,讲的非常好非常好,推荐阅读
SwiGLU 是一种门控线性单元(Gated Linear Unit, GLU)的变种,结合了 Swish 激活函数:
SwiGLU(x) = Swish(xW + b) ⊙ (xV + c)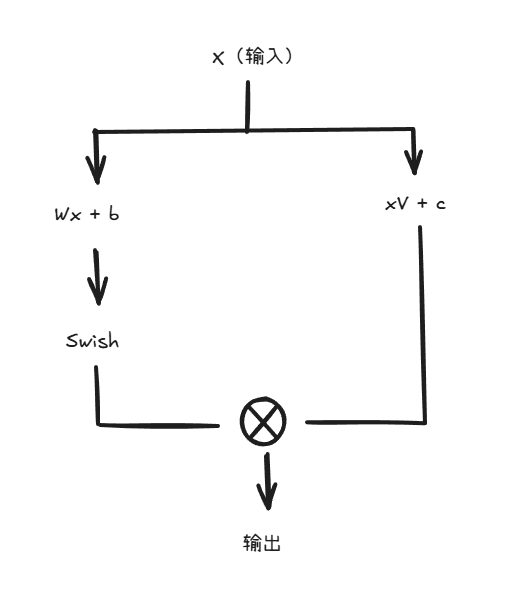
GLU 架构通过门控机制提供了更强的非线性表达能力
门控机制允许模型选择性地传递信息,类似于 LSTM 的门控
相比标准激活函数,SwiGLU 在大规模训练中表现更稳定
把swiglu和ffn融合在一起了
嗟嗟——强化学习与大模型推理你需要知道的108个问题(3. Transformer)
嗟嗟——强化学习与大模型推理你需要知道的108个问题(4. Transformer细节之问)
嗟嗟——强化学习与大模型推理你需要知道的108个问题(5. Transformer与LLM架构)
取决于多少个共享专家,比如40个,就是一个40xhead_dim的mlp层
去看下vllm里面model的实现
GQA全称grouped query attention,是一组query向量对应一对kv向量进行attention。为什么要有gqa,是因为原生的mha在存储kv向量时要求的显存较大,引入gqa可以显著减少所需的kv向量的显存占用。事实上在减少显存占用的研究路途上在gqa之前还有mqa,但是mqa在性能表现上低于原生的mha,而gqa与mha持平,甚至比原生的mha高,因此采用了gqa
参考文献:
两者的差异由颗粒度的不同,能讲的非常多,同时更新日新月异,这里的版本不一定是最全的,慢慢补吧。
(坑太大了,晚上写吧)
从PD分离开始,P和D分开来讲
参考文献:
vLLM调度器的核心任务是在每个执行步骤中,智能地从众多请求中挑选出一个组合,以填满GPU的计算能力,同时保证公平性和响应性。其逻辑围绕着prefill和decode两种不同的计算模式,以及一个固定的token预算展开。
Prefill与Decode的区分与统一: 在LLM推理中,存在两种截然不同的计算阶段 :
Prefill(预填充):处理用户输入的整个prompt。这是一个并行度很高的计算过程,所有prompt token可以一次性输入模型进行计算。这个阶段通常是计算密集型的。
Decode(解码):在prefill之后,逐个生成输出token。每次只处理一个新token,但需要依赖前面所有token的KV Cache。这个阶段是自回归的,通常是访存密集型的。
vLLM v1版本的一个重要改进是,调度器在逻辑上统一了prefill token和decode token 。它不再严格区分“prefill阶段”和“decode阶段”的请求,而是将所有需要处理的token(无论是来自新请求的prompt,还是来自正在运行请求的下一个token)都视为待处理的任务。这种统一的表示方式极大地简化了调度逻辑,并自然地支持了诸如分块预填充(Chunked Prefill)等高级功能。例如,一个非常长的prompt可以被拆分成多个块,在几个调度步骤中逐步完成prefill。
(这里可能要补一下v1新的token逻辑)
vLLM的调度器在一个循环中工作,每个循环决定一个批次(step)的执行内容。其默认调度策略是FCFS(先来先服务) 。
调度逻辑如下 :
设定Token预算:调度器在一个固定的token预算内工作,这个预算由一个关键参数max_num_batched_tokens定义。这个参数代表了单个批次中能够处理的最大token数量。
清空与排序:在每个调度周期开始时,调度器会首先将上一轮完成的请求从运行队列中移除。然后,它会将所有可运行的请求(包括等待队列中的新请求和运行队列中待生成的请求)根据调度策略(如FCFS)进行排序。
分配预算:调度器按照排序,依次遍历请求,为它们分配token处理名额,直到token预算被耗尽。
优先处理运行中请求:通常会优先为运行队列中的请求分配一个token的decode名额,因为它们是正在进行中的任务。
填充新请求:在为运行中请求分配完名额后,如果token预算还有剩余,调度器会开始从等待队列中取出新请求,为它们分配prefill名额。它可以为一个新请求分配其全部prompt长度的名额,或者在预算不足时,只分配一部分(即Chunked Prefill)。
决策生成:最终,调度器会生成一个简单的决策字典,例如{request_id_1: 1, request_id_2: 1, request_id_3: 512},表示在接下来的这一个step中,为请求1和2各处理1个decode token,为新来的请求3处理512个prefill token 。
内存检查:在做出最终决策前,调度器会与KV Cache管理器通信,确保有足够的空闲物理块来存储即将生成的KV状态。如果没有,即使token预算有余,相应的请求也无法被调度。
这种基于token预算的统一调度机制,使得vLLM能够非常灵活地在计算密集型的prefill任务和访存密集型的decode任务之间取得平衡,从而持续地让GPU处于饱和状态。
藕汤:
以step为单位,初始情况下两个队列肯定都为空,进入的request一般都是prefill,先来先得,比如budget是10个token,你的一个requeset的prefill是100,那后面进来的request都要乖乖等着,等这个request的prefill做完
p做完了会做decode,后面的request就可以进来做prefill了
当然,在prefill的阶段可以做个优化,不让其他request等太久,就是chunked prefill了
你把每个request的prefill在每次step中固定一个大小,比如5或20,这样空出来的budget可以让其他request的chunk占据
这个策略是为了应对短request的饥饿问题的
PagedAttention和Continuous Batching是vLLM性能飞跃的两大基石
PagedAttention(分页注意力):这是一种新颖的注意力算法,其核心思想借鉴了操作系统中的虚拟内存和分页机制来管理KV Cache。它将每个请求序列的KV Cache分割成固定大小的块Block(vllm里是16个kv cache一个block),这些块在物理显存中可以非连续存储。系统通过一个“块表”(Block Table)来维护逻辑块到物理块的映射关系。这种方式几乎完全消除了内存碎片,使得显存利用率接近最优(浪费低于4%),从而允许在有限的显存中容纳更多的并发请求。
PagedAttention通过极致的内存优化,极大地提升了系统能够承载的并发请求数量(即有效批次大小)
Continuous Batching(连续批处理):这是一种先进的请求调度策略,旨在最大化GPU的利用率 。vllm会把一批request的token组成一个budget的token。与等待整个budget所有请求都完成后再处理下一个budget的静态批处理不同,连续批处理在budget层面进行调度。一旦budget中的某个请求序列生成了结束符(EOS token),系统会立即释放其占用的资源,并从等待队列中填充一个新的request,使GPU始终处于满负荷工作状态 。
Continuous Batching则确保了无论请求长短如何变化,GPU的计算单元都能被这些高密度的请求持续填满。
kv cache产生的原因是通过attention的计算公式发现,每增长一个token实际上需要增多的只有Q向量,因此使用了cache技术将kv向量缓存下来来加速attention的计算。诚然kvcache的出现加速了attention的计算,但是也让gpu的显存负担明显增高。所以后面出现了GQA,mla等技术,同时kv cache的引入也产生了新的问题,如何去管理这些kv cache,kv cache的诞生使显存有了内部和外部碎片,为了解决管理的问题又引入了paged attention。
PagedAttention的原理是对操作系统中经典的虚拟内存管理思想在GPU显存管理领域的精妙应用,其核心目标是解决KV Cache动态、可变长度带来的内存管理难题。
工作流程:
内存池化:vLLM启动时,会根据可用显存和块大小,创建一个巨大的物理块池。
按需分配:当一个新请求进入(prefill阶段)或一个已有请求生成新token(decode阶段)需要更多KV Cache空间时,内存管理器会从物理块池中按需分配一个或多个空闲的物理块。
块表更新:分配到的物理块的地址会被记录在对应请求序列的块表中,与相应的逻辑块索引关联起来。由于物理块是从池中任意取出的,它们在物理显存上的地址是非连续的。
Attention计算:在执行Attention计算的CUDA/Triton Kernel中,不再传入一个连续的KV Cache张量指针。取而代之的是,Kernel会接收到这个请求的块表。当需要访问某个token的Key和Value时,Kernel会首先通过计算确定它属于哪个逻辑块,然后查询块表找到对应的物理块地址,最后在物理块内部进行偏移寻址。
PagedAttention通过以下方式有效解决了内存碎片问题 :
消除外部碎片 (External Fragmentation):所有物理块的大小都是固定的。当一个请求结束,它所占用的物理块被完整地释放回池中。由于所有空闲块都等价且可互换,系统永远不会出现“有足够总量的空闲内存,却没有一块足够大的连续内存”的窘境。
最小化内部碎片 (Internal Fragmentation):内部碎片只存在于每个序列所占用的最后一个物理块中。因为块的大小通常远小于整个序列的KV Cache大小(例如,一个块可能存储16个token的KV),所以这部分浪费的比例极低。实践中,总的内存浪费率可以控制在4%以下 。
然而,值得注意的是,PagedAttention的这种设计并非没有代价。它使得KV Cache在虚拟内存层面也变成了非连续的,这就要求Attention Kernel必须重写,以支持通过块表进行间接寻址,这会带来一定的性能开销 。
Continuous Batching(连续批处理),又称In-flight Batching,是针对LLM推理特性设计的一种高效调度策略,其核心在于将调度的粒度从“请求级”细化到“迭代级” 。
与其它批处理方式的对比 :
静态批处理 (Static Batching):服务器等待收集到固定数量的请求后,将它们打包成一个批次进行处理。整个批次必须等待其中最慢(生成最长)的请求完成后才能结束,这期间GPU资源会被严重浪费。
动态批处理 (Dynamic Batching):这是静态批处理的改良版。服务器设定一个时间窗口,处理在该窗口内到达的所有请求。这缓解了请求的等待时间,但同样存在“头节点阻塞”(Head-of-Line Blocking)问题,即批次内的短请求必须等待长请求。
连续批处理 (Continuous Batching):它彻底打破了批次的固定边界。调度器在模型的每一次前向传播(即生成一个token的迭代)后都会重新评估和组合批次。一旦某个请求完成,它的位置会立即被等待队列中的新请求填补。
vLLM的scheduler通过管理两个核心队列来实现连续批处理:
等待队列 (Waiting Queue):存放已到达但尚未开始处理的请求。
运行队列 (Running Queue):存放正在进行token生成的请求。
其分步逻辑如下:
请求入队:新的推理请求到达后,被放入等待队列。
动态批次组合:在每个生成步骤(iteration)开始时,调度器会创建一个新的批次。它会首先遍历运行队列中的所有请求,将它们加入到当前步骤的批次中。
填充批次:接着,调度器会检查当前GPU的负载和可用显存(由PagedAttention的内存管理器提供信息)。如果还有容量,它会从等待队列的头部取出新的请求,为它们分配初始的KV Cache块,并将它们也加入到当前批次中。这些新请求将执行它们的“prefill”阶段。
单步执行:组合好的批次(包含正在decode的老请求和正在prefill的新请求)被送到GPU上,执行一次模型的前向传播。、
状态更新与资源释放:执行完毕后,调度器检查批次中每个请求的状态。
如果一个请求生成了EOS token或达到了最大长度,它就被视为完成。调度器会立即释放该请求占用的所有KV Cache物理块(将其归还到内存池),并将该请求从运行队列中移除。
对于未完成的请求,它们会继续留在运行队列中,等待下一个生成步骤。
循环:调度器不断重复步骤2到5,确保GPU的计算能力在每个迭代周期都被尽可能地填满。
通过这种机制,vLLM确保了GPU不会因为等待长请求而空闲,极大地提升了系统的整体吞吐量和资源利用率,并显著降低了请求的平均延迟 。
这些CPU开销主要来源于以下几个方面 :
API服务器处理:接收HTTP请求、解析参数、管理客户端连接等。
输入预处理:对传入的文本进行分词(Tokenization),对于多模态模型还包括图像等输入的处理。
调度逻辑:运行调度算法,决定下一个批次包含哪些请求。
输出后处理:将模型生成的token ID反分词(De-tokenization)为文本。
结果流式传输:将生成的文本通过网络流式返回给用户。
在vLLM的早期版本中,这些CPU任务与GPU的模型执行任务是在同一个事件循环中串行或交错执行的。当GPU执行速度极快时,CPU就无法及时准备好下一次迭代的数据,导致GPU出现“等待CPU”的空闲气泡,从而限制了整体吞吐量。
为了解决这个问题,vLLM v1引入了更深度的多进程架构,其核心是创建了一个隔离的EngineCore执行循环 。
架构设计:系统被拆分为两个(或多个)独立的进程。一个或多个进程负责处理CPU密集型任务(如API服务器、分词/反分词),而另一个独立的进程专门运行EngineCore。
EngineCore的职责:EngineCore进程只专注于最核心的、与GPU交互的任务,即调度器(Scheduler)和模型执行器(Model Executor)。
进程间通信 (IPC):这些进程之间通过高效的IPC机制(如ZeroMQ)进行通信。API进程将分词后的请求发送给EngineCore,EngineCore执行完毕后将生成的token ID返回。
实现并行与重叠:这种架构的最大优势在于实现了CPU任务和GPU任务的真正并行。当EngineCore在GPU上执行模型前向传播时,其他进程可以在CPU上同时处理下一个请求的分词、上一个请求结果的反分词以及网络IO。CPU和GPU的工作被有效地重叠(Overlap)起来,从而掩盖了CPU端的延迟,确保了GPU能够持续不断地接收到任务,最终最大化了模型的吞吐量。
PagedAttention的性能开销来源: cuda计算中很大程度上都是使用了连续访问的内存,pagedAttention引入的blockTable就导致了合并访存率大大降低,让效率变低,每次从gmem中读数据几乎都是从不同且不连续的地址读取的,合并访存率会低很多。
额外的访存开销:在计算每个Query与Key的点积之前,Kernel必须首先访问块表,以查明存储相关Key/Value的物理块的实际地址。这是一次额外的、可能不连续的内存读取操作。
额外的计算开销:Kernel需要执行额外的指针运算和分支指令来计算正确的物理地址。vLLM的论文承认,这部分开销主要来自块表查找和额外的分支执行,导致其PagedAttention实现比原始的FasterTransformer Kernel慢了20-26% 。
对Kernel优化的阻碍:非连续的内存布局使得一些针对连续内存设计的深度优化(如向量化加载、更复杂的访存模式)变得困难或无法应用。例如,FlashAttention和FlashInfer的PagedAttention版本被证实比其原生(vanilla)版本慢12%到28% 。
vAttention的解决方案: vAttention的提出,是对PagedAttention局限性的一次深刻反思和釜底抽薪式的解决方案。其核心思想是:将动态物理内存管理的复杂性下沉到更底层的系统(GPU驱动/硬件),同时为上层的Attention Kernel保留一个简单、高效的连续虚拟地址空间 。 vAttention的工作原理如下:
保留虚拟地址连续性:与PagedAttention不同,vAttention在为KV Cache分配内存时,会请求一个巨大的、连续的虚拟地址空间。这意味着从Attention Kernel的视角看,KV Cache就像一个普通的、连续的大数组,可以直接进行高效的指针运算,无需任何块表查找。
利用按需分页(Demand Paging):vAttention并不立即为这个巨大的虚拟地址空间分配相应的物理显存。它依赖于现代GPU和操作系统已经支持的按需分页机制。只有当Kernel第一次尝试访问这片虚拟地址空间的某个页面(page)时,才会触发一个“缺页中断”(page fault),此时GPU驱动/硬件层面才会为其分配一个物理显存页面,并建立虚拟地址到物理地址的映射。
两全其美:通过这种方式,vAttention实现了两全其美的效果:
对于Kernel:它操作的是一个简单的、连续的虚拟内存布局,可以运行任何未经修改的高性能Attention Kernel(如原生FlashAttention),从而消除了PagedAttention引入的访存和计算开销。
对于系统:物理显存仍然是按需、非连续地分配的,从而同样达到了避免内存碎片、提高内存利用率的目的。
vAttention的出现,体现了系统设计中一个经典的演进模式:当一个在应用层实现的复杂抽象(PagedAttention的内存管理器)暴露出性能瓶颈时,更优的方案往往是去利用底层硬件或操作系统已经提供的、更高效的同类原生功能。
参考文献:
深入浅出GPU优化系列:elementwise优化及CUDA工具链介绍
数据并行(DP,Data Parallelism)
DP是每张卡拷贝相同的模型结构,仅对数据做切分。在训练时体现为不同batch进入不同的gpu节点进行训练,每张卡计算完的梯度也是针对各自数据的,可以通过ring all reduce方式将梯度结果传到某一张卡上进行梯度下降,下降完了还要给其他模型进行同步。
其数学基础如下:
DP特点是计算快,瓶颈就是通信带宽高
张量并行(TP,Tensor Parallelism)
tp的话是张量并行,具体表现是将模型内部的参数矩阵切分,分发到不同的gpu中。由于发放的参数矩阵是tensor,所以叫张量并行。值得注意的是tp并不是所有模块都能使用的,MLA不能用TP。
不同的模型层在TP中划分不一样,详情可以看参考文献1.
张量并行的优点是能分摊模型到多张卡上,缺点是带来了不小的通信开销,影响训练效率
流水线并行(PP,Pipeline Parallelism)
由于大模型很大程度上是重复模块的堆叠,重复的流程很多,常规的PP会增大训练的气泡率,所以要对PP进行改进,缓解每个gpu的显存压力,以及加快推理速度。具体的PP改进也是看参考文献1 。
张量并行是对矩阵进行切分,缺点是通信量很大。如果按照layer进行切分通信量就会少很多,少了同层之间的通信。
专家并行(EP,Expert Parallelism)
专家并行主要解决的是MoE模型的问题,将不同的MoE 专家放进不同的GPU,然后使用router进行分流。
参考文献:
理想使用场景:
Triton的理想场景:
快速原型验证与迭代:当需要为新的神经网络层(如FlashAttention、RMSNorm)快速开发高性能算子时,Triton的开发效率优势巨大。
深度学习研究:使研究人员能够专注于算法创新,而无需分心于底层的CUDA编程细节。
大多数DNN算子:对于常见的、结构化的计算密集型任务(如矩阵乘法、卷积、各种Attention变体),Triton的编译器优化通常足以生成接近硬件极限性能的代码。一个25行的Triton矩阵乘法算子就能达到与NVIDIA高度优化的cuBLAS库相匹配的性能 。
CUDA C++的理想场景:
极致性能压榨:当一个算子是系统的绝对性能瓶颈,且Triton生成的代码仍有优化空间时,需要用CUDA进行手动调优。
非结构化或复杂的并行模式:对于需要复杂的线程间通信、精细的Warp级操作(warp-level primitives)或不规则内存访问的算法(例如某些图算法、快速傅里叶变换FFT),Triton的高层抽象可能不足以表达最优的实现方式 。
与底层库的深度集成:当需要直接调用NVIDIA的底层库(如cuFFT, CUB)或利用特定的硬件功能时,使用CUDA是必然选择。
Triton通过其独特的块级编程模型和强大的编译器,解决的就是CUDA最麻烦的两点:内存合并和共享内存管理。为此,triton设计了两个自动优化模块:自动化内存合并 和 自动化共享内存管理。
自动化内存合并 (Automatic Memory Coalescing):
CUDA中的挑战:在CUDA中,为了实现高性能,开发者必须手动确保一个Warp(通常是32个线程)中的线程访问的是连续的全局内存地址。这种合并访问可以被GPU硬件聚合成一次或少数几次内存事务(memory transaction),从而最大化利用显存带宽。如果访问是分散的(uncoalesced),则可能导致32次独立的内存事务,带宽利用率极低 。这需要开发者精心设计线程索引和数据布局。
Triton的解决方案:Triton的编程模型操作的是数据块(tl.block),而非单个线程 。当你写下tl.load(pointer)时,你是在告诉Triton加载一个数据块。Triton编译器会接管后续工作:它分析这个块级加载操作,并自动生成底层的PTX指令,安排Warp内的线程以最优的方式(即合并的模式)从全局内存中读取数据。开发者无需关心每个线程具体加载哪个地址,只需从逻辑上操作数据块即可 。
自动化共享内存管理 (Automatic Shared Memory Management):
CUDA中的挑战:共享内存(Shared Memory / SRAM)是GPU上一种速度极快但容量很小的片上内存。为了复用数据(例如在矩阵乘法中),标准的CUDA做法是:手动声明__shared__内存数组,编写代码让线程协同地将数据从全局内存搬运到共享内存,使用__syncthreads()进行线程同步,计算完毕后再写回。这个过程非常繁琐且极易出错。
Triton的解决方案:Triton完全自动化了这一过程 。当开发者在一个Triton Kernel中加载一个数据块,并在后续的计算中多次使用它时(尤其是在计算密集型操作如 tl.dot中),Triton编译器会通过**活跃范围分析(liveness analysis)**来识别这种数据复用模式。它会自动决定将这些频繁使用的数据块“提升(promote)”到共享内存中进行缓存,而无需开发者编写任何与共享内存相关的代码。编译器会自动生成加载、同步和读取共享内存的指令。
块级编程模型 vs. SIMT模型: 这种自动化的核心在于编程模型的抽象层次不同:
CUDA的SIMT模型是以线程为中心的。它给了开发者极致的自由度,但也把优化的重担完全交给了开发者。编译器很难从单个线程的代码中推断出整个线程块的宏观协作模式。
Triton的块级模型是以数据为中心的。开发者描述的是对数据块的整体操作。这种更高层次的语义信息给了编译器更大的优化空间。编译器能够看到“加载一个tile”、“对两个tile做点积”这样的宏观意图,从而可以全局地、系统性地规划最优的数据流路径(是从HBM直接到寄存器,还是先经由SRAM)和执行策略,而这正是自动化优化的关键。
“IO感知”(IO-Awareness)是FlashAttention论文提出的核心思想,它指的是在设计算法时,必须清醒地意识到并精细地管理不同层级存储(IO)之间的 数据移动,因为这在现代GPU上是主要的性能瓶颈 。 在GPU体系结构中,存在一个显著的性能鸿沟:
高带宽内存 (HBM):容量大(几十GB),但速度相对较慢。
片上SRAM:容量极小(几MB),但速度极快,比HBM快几个数量级。
现代GPU的算力增长速度远超HBM带宽的增长速度,导致许多计算(尤其是Transformer中的操作)都受限于内存访问速度,而非浮点计算能力。因此,一个“IO感知”的算法,其首要目标就是最大化地利用快速的SRAM,最小化对慢速HBM的访问次数 。
“切片”(Tiling)技术的作用: Tiling是实现IO感知的关键技术。它通过将计算过程重构,把大的输入矩阵分解成小的块(Tiles),使得这些小块可以完全载入到SRAM中进行处理。在Attention的场景中,Tiling通过以下方式减少HBM的读写 :
避免物化巨大的Attention矩阵:标准的Attention实现会计算并向HBM写入一个大小为 N×N 的Attention Score矩阵(N为序列长度)。当N很大时,这个矩阵会占用巨大的显存(O(N2)),并且读写它会消耗大量的HBM带宽。Tiling技术通过分块计算,完全避免了将这个巨大的中间矩阵写入HBM。
分块计算流程:FlashAttention的Kernel并不会一次性处理整个Q, K, V矩阵。相反,它的外层循环遍历K和V矩阵的块(Tiles)。
在每次外层循环中,它将一个K块和一个V块从HBM加载到SRAM中。
然后,内层循环遍历Q矩阵的块。在每次内层循环中,它将一个Q块加载到SRAM。
在SRAM内部,这个Q块与已加载的K块计算出局部的Attention Score,并用这个Score去加权V块,得到一个局部的输出结果。
这个局部输出结果会与之前所有块计算得到的累积结果进行合并。
在线Softmax (Online Softmax):Softmax操作需要对一行中的所有元素进行归一化,这看似需要完整的N×N矩阵。FlashAttention巧妙地通过一种数值稳定的在线算法,在逐块计算的过程中,只维护和更新行最大值和归一化因子这两个小的中间状态,从而在不看到完整矩阵的情况下,也能计算出正确的Softmax结果。
为反向传播重计算:为了进一步节省显存,FlashAttention在反向传播时不会从HBM读取前向传播时计算的N×N Attention矩阵(因为它根本就没存)。取而代之的是,它利用前向传播时保存的Softmax归一化因子,在SRAM中重新计算所需的Attention值。虽然这增加了浮点运算量(FLOPs),但由于避免了大量的HBM读操作,总的执行时间反而更快。
综上所述,Tiling通过将计算分解为可以在高速SRAM中完成的多个小任务,极大地减少了对慢速HBM的依赖,是实现IO感知算法的核心手段。
@triton.autotune 自动调优: @triton.autotune是一个装饰器,它能自动为Triton Kernel寻找最优的配置参数组合 。
工作原理:开发者可以为Kernel定义一组triton.Config对象。每个Config对象代表了一套不同的“元参数(meta-parameters)”,例如BLOCK_SIZE_M, BLOCK_SIZE_N, num_warps等。当被@triton.autotune装饰的Kernel首次以特定输入尺寸运行时,Triton会为每个Config配置编译并运行一个微基准测试(micro-benchmark),然后缓存下性能最好的那个配置。后续所有相同输入尺寸的调用都将直接使用这个最优配置。
使用方法:
Python
@triton.autotune(
configs=,
key=['M', 'N', 'K'], # 根据这些输入参数的值来缓存最优配置
)
@triton.jit
def matmul_kernel(A, B, C, M, N, K,...):
#... kernel code
重要性:最优的配置参数高度依赖于具体的GPU架构(如SM数量、SRAM大小)和输入张量的形状。手动寻找最优值是一个极其繁琐的过程。Autotuning将这个过程自动化,使得编写的Kernel能够自适应地在不同硬件和不同问题规模上都达到接近最优的性能。
算子融合是将多个独立、连续的计算操作合并到一个单一的GPU Kernel中执行的技术 。
解决的问题:
Kernel启动开销 (Launch Overhead):每次从CPU调用一个GPU Kernel都有一定的开销(几微秒)。对于许多计算量不大的“逐元素(element-wise)”操作(如加法、ReLU激活),这个启动开销甚至可能超过实际的计算时间。
内存流量 (Memory Traffic):在未融合的情况下,每个算子的输出结果都必须先写回慢速的HBM,然后下一个算子再从HBM中把它读出来。这一来一回的读写是巨大的性能浪费。
融合后的优势:
通过将例如Matmul -> Bias Add -> ReLU这三个操作融合成一个Kernel,我们只需要一次Kernel启动。
更重要的是,Matmul计算出的中间结果可以直接保存在GPU核心的高速寄存器(registers)或SRAM中,然后立即用于Bias Add和ReLU的计算,最后才将最终结果写回HBM。这完全消除了中间结果在HBM上的读写,极大地节省了显存带宽 。
BLOCK_SIZE)?为了最小化内存访问,您会融合哪些关键操作?RMS公式如下:
y_i=\frac{x_i}{\sqrt{\frac{1}{n}\sum_{j=1}^nx_j^2+\epsilon}}\cdot g_i
并行维度:RMSNorm是在最后一个维度(ModelDim,即特征维度)上进行归一化的。因此,我会让每个Triton程序实例(program instance)负责处理一个token的归一化。并行化将在Batch和Sequence Length维度上展开。
数据加载:在Kernel内部,每个程序实例会加载其对应token的完整特征向量(长度为ModelDim)。
块内计算 (Tiling):由于ModelDim可能很长(例如4096或更大),无法一次性加载到寄存器中。因此,我会使用Tiling技术。程序将以BLOCK_SIZE为单位,分块加载这个特征向量。
# 伪代码
row_ptr = X + pid * stride_x # 指向当前token的特征向量
accumulator = 0.0
for offset in range(0, D, BLOCK_SIZE):
# 1. 加载一个数据块
mask = tl.arange(0, BLOCK_SIZE) + offset < D
x_chunk = tl.load(row_ptr + offset, mask=mask, other=0.0)
# 2. 在寄存器中计算平方和
accumulator += tl.sum(x_chunk * x_chunk)
块间归约 (Reduction):上述循环计算了每个程序实例的局部平方和。如果使用了多个Warp,还需要在Warp之间进行一次归约,得到整个向量的平方和。
归一化与写回:得到总的平方和后,在寄存器中完成后续的Mean, Add Epsilon, Rsqrt计算,得到归一化缩放因子。然后,再次以BLOCK_SIZE为单位循环遍历特征向量,加载x_chunk和对应的g_chunk,在寄存器中完成归一化和缩放,最后将结果写回输出地址。
BLOCK_SIZE的选择: BLOCK_SIZE是性能的关键。
选择依据:它应该是一个2的幂次方,以便于编译器优化。其大小需要在多个因素间权衡:
L1缓存/共享内存容量:选择的BLOCK_SIZE以及相关的中间变量应能很好地装入L1缓存或共享内存,以最大化数据复用 。
寄存器压力:过大的BLOCK_SIZE可能导致寄存器溢出(spilling)到本地内存,反而降低性能。
并行度:BLOCK_SIZE决定了每个线程块内部的并行度。
调优方法:我会将BLOCK_SIZE作为一个可调参数,并使用@triton.autotune来系统性地测试一系列候选值(例如,128, 256, 512, 1024),让Triton自动找到在目标硬件上针对特定ModelDim的最优值 。 (看最后一个问题)
roofline模型事实上是斜线和一条横线。横坐标一般是计算强度,纵坐标是性能,一般都是每秒硬件能做多少操作
斜线部分表示模型处于memory bound,这个时候可以通过增加计算强度让模型性能提高,具体方法比如增大gemm的矩阵大小,当遇到横线时说明达到了comoute bound了,此时模型性能已经达到理论极限。计算强度的提高对性能的提高已经没有什么帮助了
选择合适的block size可以让模型接近拐点
理想回答:
这是一个典型的多租户、高并发、模型动态加载的复杂场景,对推理系统的灵活性和性能都提出了极高的要求。我的设计方案将围绕以下几个核心原则展开:权重共享、动态适配、批处理优化和算子融合。
1. 推理引擎选择:vLLM 我将选择vLLM作为基础推理引擎。主要原因在于其成熟的社区生态和对多LoRA推理的内建支持 。vLLM允许在服务启动时加载基础模型,并在运行时动态加载和切换不同的LoRA适配器,这完美契合了本场景的需求。其PagedAttention和Continuous Batching机制是实现高吞-吐和低延迟的基础保障。
2. 权重和适配器管理策略:
基础模型权重共享:基础模型的权重是所有用户共享的,体积巨大。它将在服务启动时被加载到所有GPU上,并保持不变。如果模型过大,将采用Tensor Parallelism进行分布式加载 。
动态LoRA适配器管理:LoRA适配器的权重(A和B矩阵)体积很小(通常只有几MB)。
LoRA缓存:我会在CPU内存中设计一个LRU缓存,用于存放最近使用过的LoRA适配器权重。当一个请求到达时,如果其所需的LoRA适配器不在缓存中,系统会从持久化存储(如S3)中加载它。
GPU动态加载:当一个携带特定LoRA的请求被调度执行时,vLLM的LoRA管理器会确保该LoRA的权重被加载到GPU显存中。为了避免频繁的CPU到GPU的数据传输,GPU上同样可以设计一个LoRA权重缓存池。
PagedLoRA(进阶思路):可以借鉴PagedAttention的思想,将GPU上的LoRA缓存池也用“分页”的方式管理起来。将不同的LoRA权重矩阵也切分成固定大小的块,按需加载到GPU。这可以更精细地管理GPU显存,容纳更多的LoRA适配器。
3. 调度策略优化: 默认的FCFS调度策略在此场景下可能不是最优的。因为频繁切换LoRA适配器会带来权重加载和计算流水线刷新的开销。
LoRA感知调度 (LoRA-Aware Scheduling):我会修改或扩展vLLM的调度器,使其具备LoRA感知能力。调度器在组合批次时,会优先将使用相同LoRA适配器的请求打包在一起。这可以最大化每个LoRA权重的复用率,最小化切换开销。可以为每个LoRA维护一个独立的等待队列,调度器轮流或按优先级从这些队列中抽取请求。
4. 自定义算子优化: LoRA的计算核心是在Transformer的每一层中,将原始的权重矩阵W0替换为W0+ΔW=W0+BA。对输入x的计算变为y=xW0+xBA。这里存在显著的算子融合机会。
Fused LoRA Kernel (Triton实现):我会使用Triton编写一个融合的算子,来高效地执行xBA这部分计算。
输入:该算子将接收输入x、LoRA的A矩阵和B矩阵。
融合操作:在一个Kernel内部,完成两个连续的矩阵乘法:
计算中间结果 z=xB。这个中间结果将保留在高速的SRAM或寄存器中。
立即计算最终结果 out=zA。
优势:这个融合算子避免了将巨大的中间结果xB写入和读出HBM,极大地节省了显存带宽,对于访存密集型的decode阶段尤其重要。相比于PyTorch中两次独立的torch.matmul调用,性能会有显著提升。
Fused LoRA Add Kernel:更进一步,可以将LoRA的计算结果与基础模型的计算结果xW0的相加操作也融合进去。即设计一个算子,输入为x,W0,B,A,输出为xW0+xBA。这需要修改模型底层的线性层实现,但能最大程度地减少内存移动。
通过这套结合了vLLM引擎、优化的调度策略和定制化Triton算子的系统设计,我们可以构建一个既能灵活支持海量LoRA适配器,又能保持高吞吐和低延迟的、生产级的多租户推理服务。
